Bert⚓︎
约 2748 个字 2 张图片 预计阅读时间 9 分钟 总阅读量 次
BERT 的出现可以说是 NLP 领域进入“大模型时代”的开端。其思想类似CV的那一套:先训练出一个强大的预训练模型,然后再微调出子问题结果。它提出的思想深刻地影响了后续所有的预训练模型。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arxiv. 2018.10. Google. 一个预训练的、深的、双向的、Transformer 架构的、 用于语言理解的模型。
背景⚓︎
ELMo的工作(基于RNN的)、GPT-1(单向Transformer) 的工作。而 Bert 的工作则是双向的语言理解 ,并且只需要加一个额外的输出层就可以取得许多SOTA。
对于把预训练模型用到下游任务中,两个做法,ELMo 的基于特征的;GPT 的基于微调的。
对于单向的,实际上一些下游任务是不符合这种假设的。诸如完形填空、QA问答。如果放两个方向的信息,或许可以提升性能。
作者认为的贡献:
- 展示了双向信息的重要性。
- 证明了如果有一个好的 Pre-Training 模型,那么以他进行微调,可以解决许多NLP 相关的问题。比如Bert就是第一个拿到众多SOTA的基于FT的模型。
- 使用非监督的预训练同样是很好的,在大量非标号数据的模型性能和水平,甚至可能好于在少量标号数据的结果。
1. BERT 的模型网络架构⚓︎
一言以蔽之:BERT 的网络架构就是原始 Transformer 的编码器 (Encoder) 部分的堆叠。 讲细了是一个多层的双向编码器 (Multi-Layer Bidirectional Transformer Encoder) 。
是的,就是这么简单。BERT 摒弃了 Transformer 的解码器 (Decoder) 部分,只使用其 Encoder。一个典型的 BERT-Base 模型会堆叠12个 Encoder 层,而 BERT-Large 则会堆叠24个。
让我们回顾一下 Transformer Encoder 的单层结构:
输入 -> 多头自注意力 (Multi-Head Self-Attention) -> Add & Norm -> 前馈神经网络 (Feed-Forward Network) -> Add & Norm -> 输出
BERT 就是把这个结构重复N次。
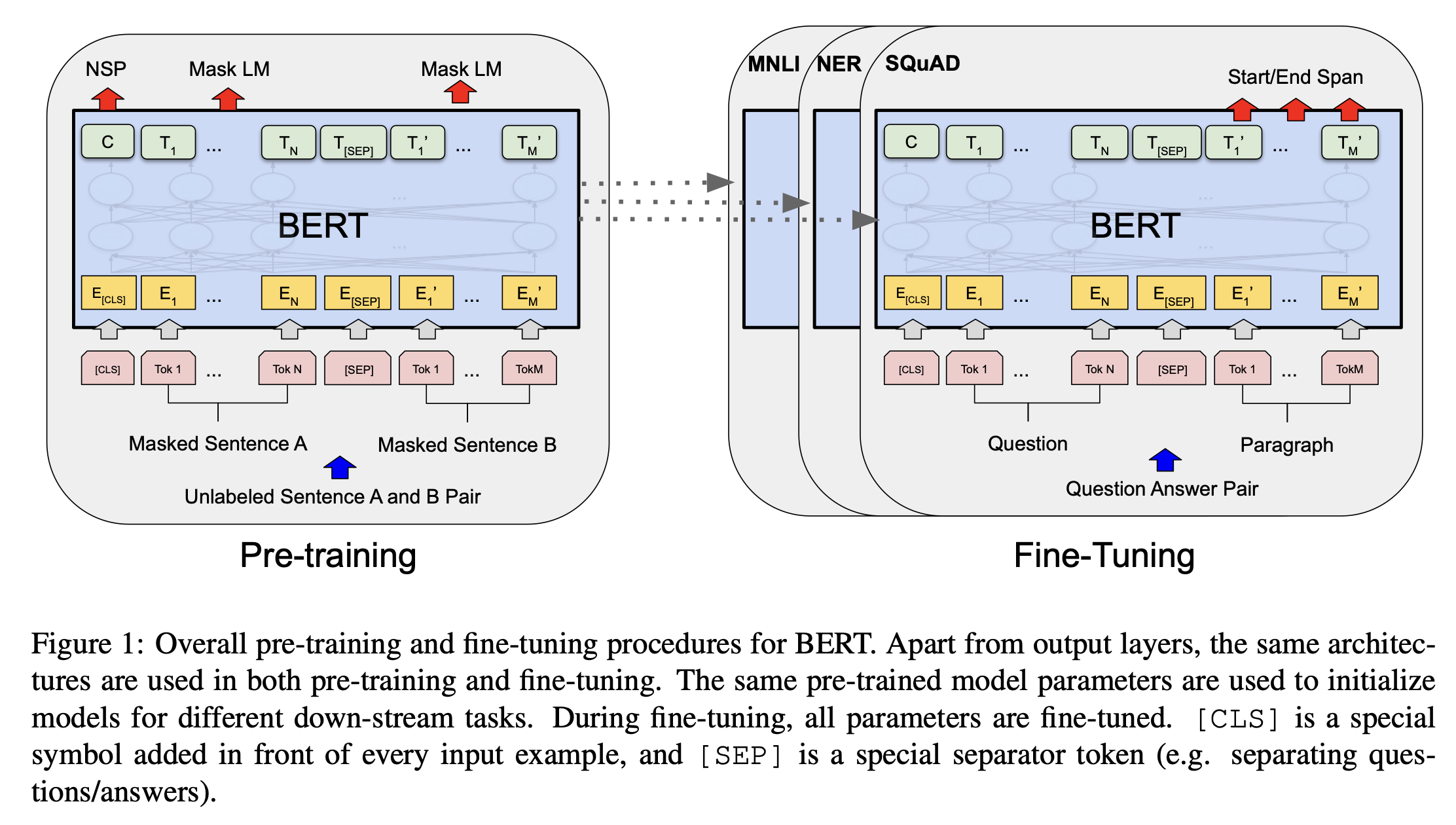
这个图其实还很适合讲解预训练和微调。
首先基于未标号数据训练一个Bert 模型(以MLM和NSP为任务),这就是 Pre-Training。对于所有下游任务,都声明一个一样的 Bert 模型。按照这个 Bert 模型的权重去初始化模型,在特定的任务上,利用有标号的数据进行训练。架构上只需要加上输出层。微调时候对权重进行调整。就够了,这就是 Fine-Tuning。
2. 相比 Transformer 的改进⚓︎
虽然核心组件没变,但 BERT 在如何使用这些组件,以及训练目标上做出了革命性的改进。这正是它的精髓所在。
| 方面 | 原始 Transformer | BERT |
|---|---|---|
| 模型结构 | Encoder + Decoder (用于Seq2Seq任务) | 仅 Encoder (用于语言理解) |
| 核心思想 | 一种通用的序列到序列转换架构 | 通过深度双向预训练,生成通用的语言表示 |
| 信息流 | Encoder是双向的,Decoder是单向(自回归)的 | 完全双向,模型在处理一个词时,能同时看到其左右两边的所有上下文 |
| 预训练任务 | 无(原始论文中没有预训练概念) | Masked Language Model (MLM) + Next Sentence Prediction (NSP) |
| 位置编码 | Sinusoidal (三角函数) | Learned Positional Encoding (可学习的位置编码),与词嵌入一起训练 |
| 输入表示 | Token Emb + Positional Emb |
Token Emb + **Segment Emb** + Positional Emb |
WordPiece Embedding⚓︎
见 Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arxiv. 2016.09. Google.
一种切词的方法。假设按照空格切词(以英文为例),一个词是一个Token,词数量特别多,可能导致词典爆炸。此时模型可学习参数就集中在词的 Embedding 上了。此时可以这样缓解:如果一词出现概率不大的话,应该把词切开只看它的子序列(类似词根)。这样就可以用更少数量的词来表示文本了。
比如,carelessness, 就可以视为 careless + ness 的拼接。strawberry => straw + berry. 以此类推。
3. BERT 的任务⚓︎
最重要的改进:BERT 重新定义了模型的“目标”。原始 Transformer 是为了“翻译”等特定任务服务的。而 BERT 的目标是,通过两大创新的预训练任务,让自己成为一个通用的、深刻理解自然语言的“语言理解专家”。为了实现真正的双向理解,BERT 设计了两个预训练任务。
Masked Language Model (MLM) - 掩码语言模型⚓︎
这是 BERT 的核心创新。传统的语言模型为了预测下一个词,只能看左边的信息(单向)。如果允许它看到右边的词,那预测就变成了“作弊”。
BERT 的做法是:故意遮住(Mask)句子中的一些词,然后让模型去预测这些被遮住的词是什么。
这就像做“完形填空”题。为了填对空,你必须深刻理解整个句子的上下文,包括前和后的信息。(作者甚至提到了1953年的一个叫 Cloze 的任务)
- 具体流程:
- 随机选择输入句子中 15% 的 Token。
- 对于这 15% 的 Token:
- 80% 的概率,用一个特殊的
[MASK]标记替换掉它。我爱学习 -> 我爱 [MASK]习 - 10% 的概率,用一个随机的词替换它。
我爱学习 -> 我爱 [苹]习(这能增强模型的纠错能力,迫使其更依赖上下文) - 10% 的概率,保持原样。
我爱学习 -> 我爱学习(这为了减轻[MASK]标记带来的预训练-微调阶段不匹配问题1)
- 80% 的概率,用一个特殊的
- 模型的训练目标就是准确预测出这些被修改位置的原始单词。
Next Sentence Prediction (NSP): 下一句预测⚓︎
MLM 关注于词级别的理解,而 NSP 则让 BERT 理解句子与句子之间的关系。这对于问答(QA)、自然语言推断(NLI)等任务至关重要。简而言之,给两个句子,判断两个句子在文中是否是相邻的。
-
具体流程:
- 构造训练样本时,输入两个句子 A 和 B。
- 50% 的概率,句子 B 是句子 A 在原始语料中的真实下一句 (标签为
IsNext)。 - 50% 的概率,句子 B 是从语料库中随机抽取的一个句子 (标签为
NotNext)。 - BERT 需要预测 B 是否是 A 的下一句。这个预测任务通常是利用一个特殊的
[CLS]标记的输出来完成的。
-
后续发展:后来的研究(如 RoBERTa)发现 NSP 任务可能过于简单,甚至会损害模型性能,因此许多后续模型放弃了 NSP。但它在 BERT 原始设计中是重要一环。
4. BERT 的架构和流程梳理⚓︎
整个 BERT 的生命周期分为两个阶段:
阶段一:预训练 (Pre-training)
- 输入:海量的无标签文本(如维基百科、书籍)。
- 输入格式:每个输入样本包含一到两个句子,并加入了特殊标记:
[CLS]:加在整个输入的开头,其对应的最终输出向量被用作整个序列的聚合表示,用于分类任务 (classification)。[SEP]:加在句子之间,以及整个输入的末尾,用于区分开句子 (separate)。- Segment Embedding: 为每个 Token 额外增加一个段落嵌入,用于区分它是属于句子A还是句子B。
- 流程:
- 将输入文本处理成
Token Embedding + Segment Embedding + Position Embedding的总和(解释见下)。 - 将处理后的向量序列喂入 N 层的 Transformer Encoder。输出一个大小为句子长度 * Hidden_dim 的矩阵。
- 使用最终的输出向量,同时计算 MLM 损失和 NSP 损失。
- 根据总损失,反向传播更新模型所有参数。
- 将输入文本处理成
- 产出:一个预训练好的、包含了丰富语言知识的 BERT 模型。这个阶段极其耗费计算资源。
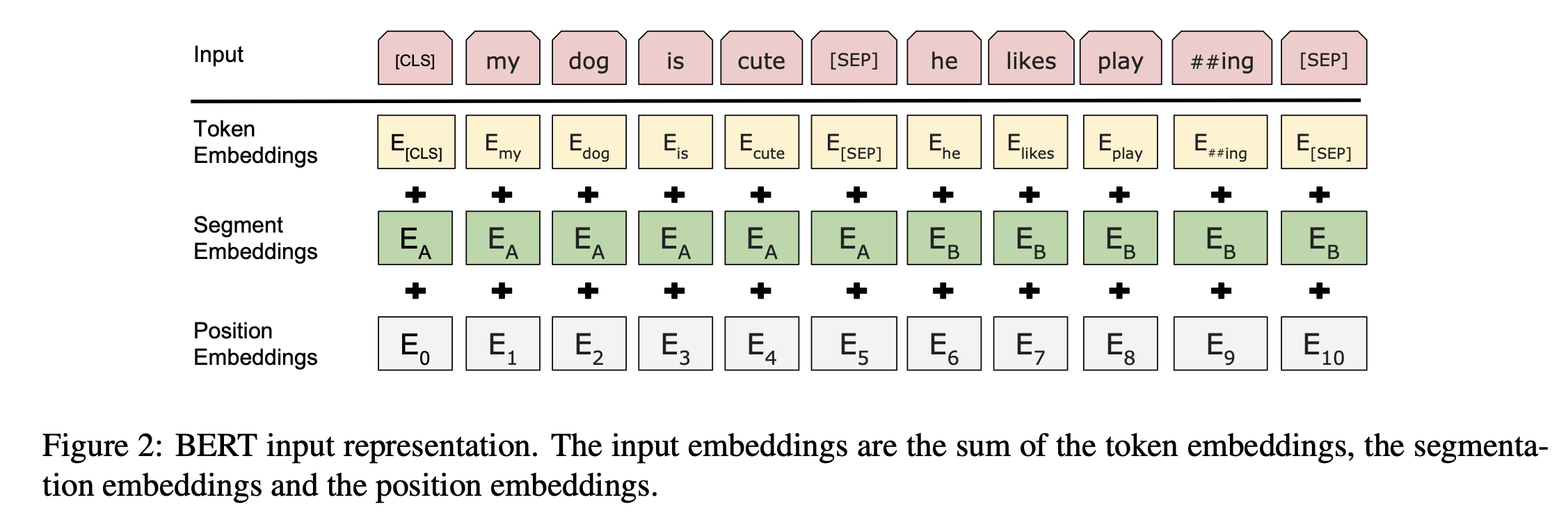
详细展开一下嵌入层的做法。 给一个词元的序列,然后得到向量序列。这里分了三个 Embedding。
- Token Embedding,就是词本身的 Embedding,这个参数毫无疑问是可以学习的 ;
- Segement Embedding,表示第一句话还是第二句话,每一句话的每个Token 这个 Embedding都相同,这个参数也是可以学习的;
- Position Embedding,就是位置编码,不同于 Transformer 的绝对编码,这里一开始就以 0, 1, 2 ... 标志这个 Token 在这个句子里的位置。但是这个位置向量的表示参数是可以学习的。
阶段二:微调 (Fine-tuning)
- 输入:针对特定下游任务的少量有标签数据(如情感分类、命名实体识别)。
- 流程:
- 加载预训练好的 BERT 模型。
- 根据具体任务,在 BERT 的输出层之上增加一个简单的、未训练的分类层(比如一个全连接层+Softmax)。
- 用任务相关的标注数据,对整个模型(或主要只对顶部的分类层)进行训练。由于 BERT 已有很好的语言理解基础,这个过程通常很快,需要的数据也少。
- 产出:一个在特定任务上表现优异的“专家”模型。
数据集/上下游任务⚓︎
BookCorpus (800 M 字) 和 Wikipedia (2500 M 字, 英文)。
对于下游任务而言,模型其实不需要变,要做的事是:
- 对于特定的下游任务构建特定的输入和输出。比如句子对,或者单个句子分类的话就用第一个
[cls]这个 Token,后面接输出层 + softmax 进行分类即可;
Bert论文本身也提到了如何对一些其他特定任务构建。比如sQUaD数据,要找到问题在给定句子开始和结束的一句话作为回答。那么要做的就是学2个向量 s, e,分别是Token为答案开始和结束的概率。对每个 Token,相乘后做 softmax 即可。
5. BERT 在哪些任务上有改进?它的特点是什么?⚓︎
-
改进的任务:BERT 在几乎所有的自然语言理解 (NLU) 任务上都取得了当时 SOTA (State-of-the-art) 的效果,血洗了 GLUE、SQuAD 等权威榜单。这些任务包括:
- 句子级分类:情感分析、文本分类。
- 词级分类:命名实体识别 (NER)。
- 句子对分类:自然语言推断 (NLI)、句子相似度判断。
- 问答:抽取式问答 (Extractive QA),如 SQuAD。
-
核心特点总结:
- 真正的双向性:通过 MLM 机制,是第一个真正实现了深度双向上下文表示的模型。
- 预训练-微调范式:奠定了现代 NLP 大模型“大规模预训练 + 少量数据微调”的黄金范式。
- 通用性:同一个预训练模型,只需微调即可适配大量不同的下游任务,实现了极大的模型复用。
- 非生成式:BERT 是一个强大的理解模型,而不是像 GPT 那样的生成模型。它的架构不适合做长文本生成。
-
因为微调时候不一定有
[Mask]这个东西,所以FT阶段看到的东西和预训练时模型看到的东西可能有些不一样。这个时候就可以通过这种办法来缓解。 ↩