GPT⚓︎
约 2658 个字 6 张图片 预计阅读时间 9 分钟 总阅读量 次
| Notes | GPT-3 (175B) |
GPT-2 (1.5B) |
GPT-1 (117 M) |
Bert (340M) |
Transformer |
|---|---|---|---|---|---|
| Attention | Sparse Attn | Dense Attn | Dense Attn | Bi-Dense Attn | Bi-Dense Attn + Cross Attn + Dense Attn |
| Head | 96 | 25 | 12 | 16 | 8 |
| Hidden dim | 12288 | 1600 | 768 | 1024 | 512 |
| FFN dim (~ 4 * Hidden dim) |
49152 | 4800 | 3072 | 4096 | 2048 |
| Layer | 96 | 48 | 12 | 12 | 6 |
| Positional Embd | - | Learnable | Learnable | - | sinusoidal |
| Context Length | 2048 | 1024? | 512 | - | -- |
| Vocabulary Size | 50257 | 50257 | ~30000 | ~30000 | -- |
GPT-1⚓︎
问题 / 背景 / 简介⚓︎
Improving Language Understanding by Generative Pre-Training, 2018.06,Links, Code (By A.K.)
NLP领域的一个问题是,尽管有不少标好的数据,但是还是太少了,我们必须在标好的数据上训练分辨模型比较难。
解决这个问题的思路就是,在一些没有标号的数据上预训练一个语言模型 (Language Model),再利用有标号的数据,在预训练的模型基础上微调一个分辨模型 (Discriminative Fine-Tuning Model),文中描述整个流程为“半监督学习(Semi-supervised Learning) 1”的方法。而 GPT-1 和先前工作的一个区别是,只需要在微调阶段构造和任务相关的输入,这样只需要很小地改变我们的模型架构即可。
先前工作遇到的问题
- 无标号任务难以选择合适的目标函数。
- 如何把学习到的特征表示传递到下游不同的子任务里。
这是因为NLP的子任务差别很大,需要对词做判断的,对文本做分类的、文本生成的等等。
架构 / 任务⚓︎
模型架构选择了 Transformer,因为作者认为相比RNN,Transformer有更加结构化的记忆,能处理更长的文本信息,能抽取出更好的句子、段落层面的寓意信息。 因此特征的学习相比RNN会更加稳健一些。
在无监督的预训练部分,目标函数是找到参数使得能够在给定前面一部分文本时,输出的后面的文本和原先后面的文本尽可能大概率地相似。
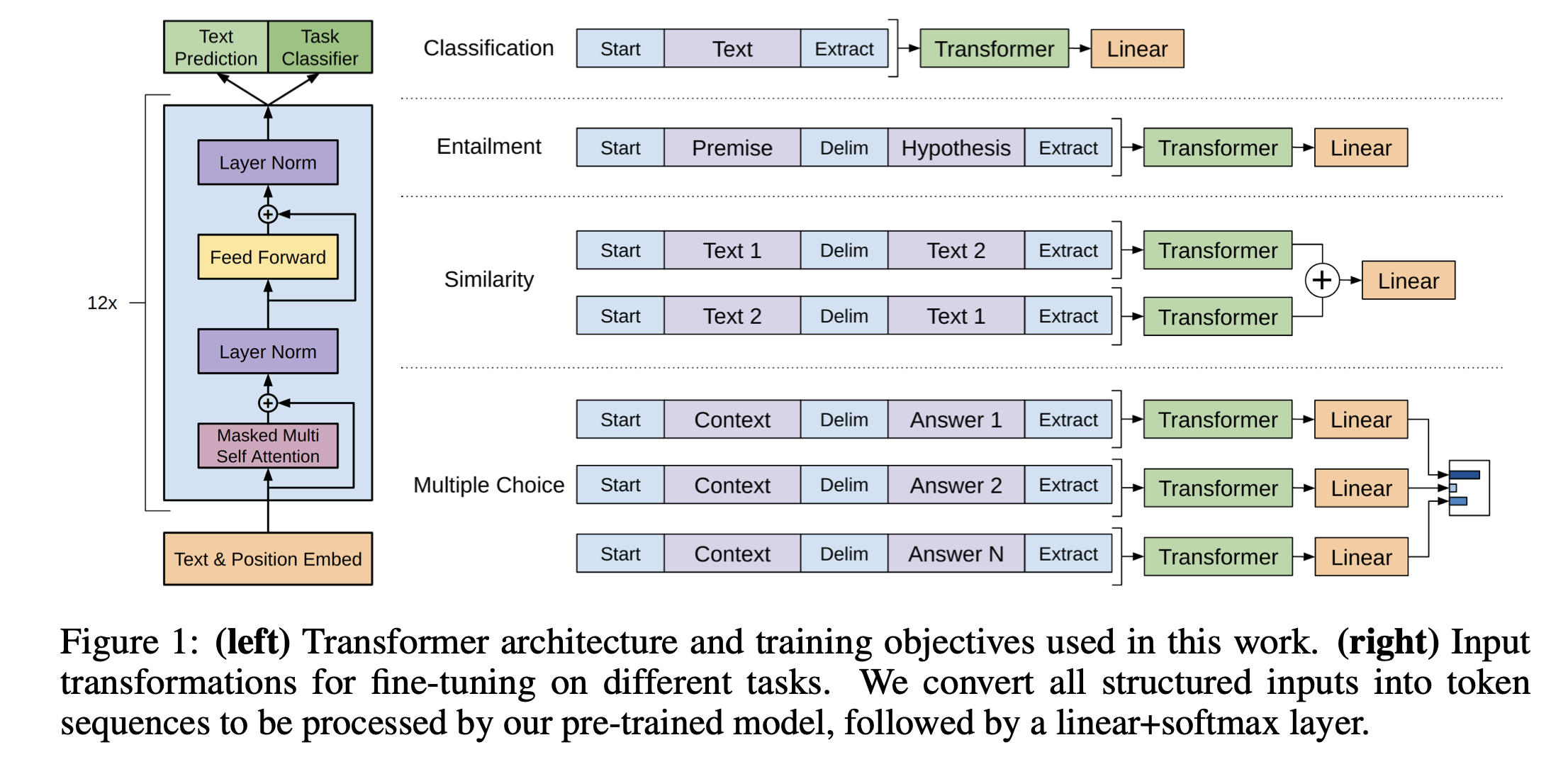
具体而言,模型架构是 Transformer 的解码器 (Decoder)。也就是,我们在第 i 个词进行预测时,只能看到前面窗口内的词,不看后面的词,Mask 机制会把后面的词设为0。同样地,因为没 Encoder 了,所以这个架构里自然没有Cross Attention 操作了。只有 Masked Multi Head Attention 。
要点: (1). Positional Embedding, (2). Masked Multi Head Attention (only), (3). Layer Norm, (4). Feed Forward Network; (4). 12 个 Transformer Block;(5). 四个下游任务的微调 (针对数据的预处理);
参数: 1 亿个参数 (100 Million); 5GB 的训练数据;
这里值得一提的是和 Bert 的区别,一方面当然有 Encoder / Decoder 架构 (Architecture) 的不同,但是还有一层是目标函数的不同,Bert 是“完形填空” (Masked Language Model ,故意遮住句子中的一些词,然后让模型去预测这些被遮住的词是什么),而 GPT 是预测未来 。从任务上讲GPT更难一些。
到了监督学习的微调阶段,数据是有标号的,需要针对给定的文本,尽可能输出和标号相符合的内容。 实现起来其实很简单,将最后一个 Transformer 块的输出,乘以一个输出层,做 softmax 就可以得到概率了。这个任务想要最大化的就是这个概率。
注意,实际做的时候发现,微调时候有2个目标函数,一起训练效果最佳,一个是给一个序列预测标号,一个是给一段话预测下一个词。
如何表示 NLP 常见的下游任务,构造标号数据?
见前图,分了 4 种常见任务:
- 分类
- 判断文本的标号(情绪、分类等)。结果会通过 Linear (一个新的线性层!)投影到一个类别的子空间;
- 蕴含
- 给一段话以及给一个假设,需要判断一段话里是否支持/反对/不支持不反对这个假设;做的时候实际上是把文本用特殊记号进行分割拼成一个句子。
- 相似
- 广泛应用,判断文本(搜索词)和文本(文档)是否相似。 因为a相似b说明b也相似a,因此可以做成两个序列,两个序列分别进入模型得到2个结果,做加号得到最终的结果。
- 多选题
- 一个问题,几个答案,选择正确的答案。比如N个答案,就构成N个序列。这 N 个序列的结果都进入模型+线性层,对输出的向量 做softmax就知道选择每个答案的概率了。
你可以发现,不管任务怎么变,变的都是构造出的序列,而中间的Transformer都是不变的,也就是预训练的模型在下游任务上不变。
数据集:【待补充】 。
GPT-2⚓︎
Language Models are Unsupervised Multitask Learners , 2019.02. Links
主要的卖点(创新点)是 Zero-Shot。
作者说当时(NLP)的主要做法是对一个任务收集一个专门的数据集然后在上面微调,这是因为当时模型的泛化性不是很好,必须要微调;彼时也已经有了多任务学习的观念 (Multi Task Learning),比如可能多个损失函数,多个数据集来实现。 不过这在 NLP 里用到得不多。
总结而言这么搞有俩问题:1. 每一个任务都要重新微调;2. 每一个任务都要搜集有标号的数据。 也就是,拓展到新的任务上的成本较高。
GPT-2要做的就是,依然做一个语言模型,不过我是 Zero-Shot 的。也就是,做下游的任务时不需要下游的任何有标号数据,也不需要去训练模型。
这就导致:没法在下游任务引入分隔符、开始和结束符,这就要求需要提前把下游的输入构造成预训练的文本长得类似。譬如,我可以把翻译任务表达成:(Translate Text, English sentence, French sentence),这就像一个 Prompt。
作者就认为,通过学习,模型能够从中学到这个任务本身,理解提示符干的事情,从而能够输出你想要的结果。
要点: 架构上和GPT-1类似,训练Trick上稍有不同;重点是取消了微调,完全zero-shot,引入了Prompt;更多的模型参数、更大的训练数据。
Tricks 包括: 1. Post-Norm 变成了 Pre-Norm (依然是LayerNorm不过改变了位置); 2. 残差层的初始化参数随着层增加而减小 (除以 \(\sqrt{n}\),其中 \(n\) 为残差层的层数) 3. 更大的词典;
参数: 15 亿个参数 (1.5 B illion); Reddit的优质的网页数据。800万文本,40GB的文字。
【补充数据集。CommonCrawl, Reddit,如何利用Karma信息(类似评论质量)提取高质量数据、提高信噪比】
模型参数:

模型效果:
GPT-3⚓︎
Language Models are Few-Shot Learners. 2020.06. Links.
弥补了 GPT-2 在有效性上的不足。
GPT-3 是一个自回归的、有1750亿参数的语言模型。因为模型参数很大,在涉及到子任务的时候,不进行梯度更新、不进行微调。
事实证明,效果很好,并且能生成一些人类都很难区分真假的新闻文章。
问题 / 背景 / 简介⚓︎
简单回顾先前做法:搞一个预训练语言模型,在子任务上做微调。这个存在问题:
- 需要与任务相关的数据集、微调,这就有标号的问题;
- 在微调后效果好了,不代表预训练模型的泛化性就好,很可能是通过微调它过拟合了微调的训练数据,而你的训练数据和你的下游任务刚好具有一定的重合性。 这导致微调后效果很好。譬如,你换到一个其他语言、其他专业里的任务,就未必那么好了。此时,我们或许需要直接比拼预训练模型的泛化性。
- 人类不需要一个超级大的数据集来做任务,或许只需要简单的例子就行了。
于是,文章定义了 In-context Learning,上下文学习。尽管我有 Few-Shot,但是我不对模型权重做任何的更新,不进行梯度传导。
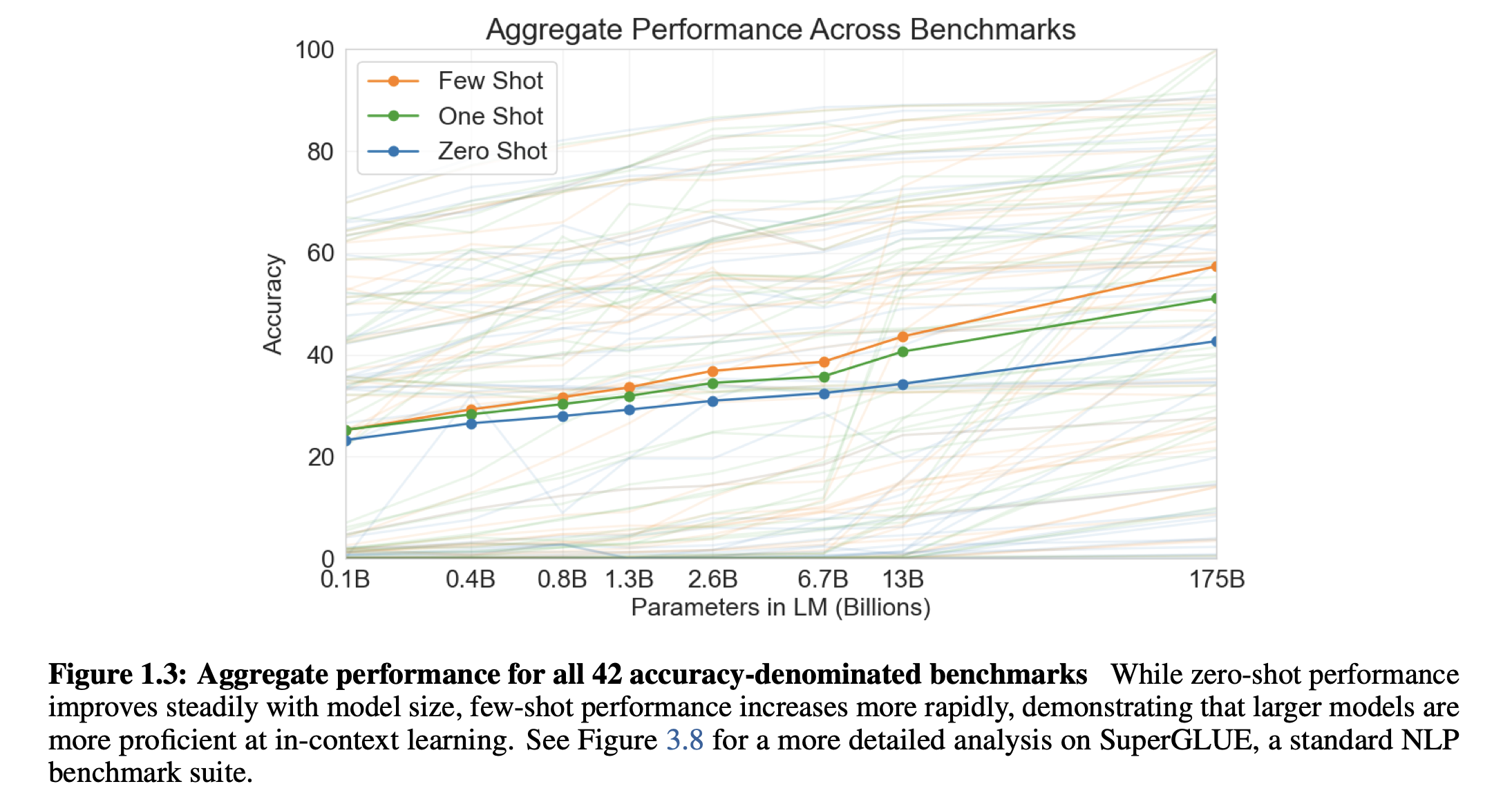
什么是Few- Shot / 1-Shot
Few-Shot: 每个子任务给提供10~100个小的训练样本;
One-Shot: 每个子任务只给提供1个训练样本;
清洗数据的Trick:
- 筛选:CommonCrawl的数据,把它的样本作为负例,把 GPT-2 用的 Reddit 高质量的数据作为正类,进行简单的 Logistics Regression,判断为正则保留,否则删除;
- 去重:如果一个文章和另一个文章很相似的话,那么就去除 (LSH算法 (Local Sensitive Hash) ,快速判断一个集合和另一个大集合的相似度);
- 补充:采纳原先 Bert,GPT-2等用过的高质量数据集,比如 Books,Wikipedia 的数据等等;
- 采样:不同类的数据集有不同的采样方法:高质量的权重高,低质量的权重低(虽然数量更多);
有趣的结果⚓︎
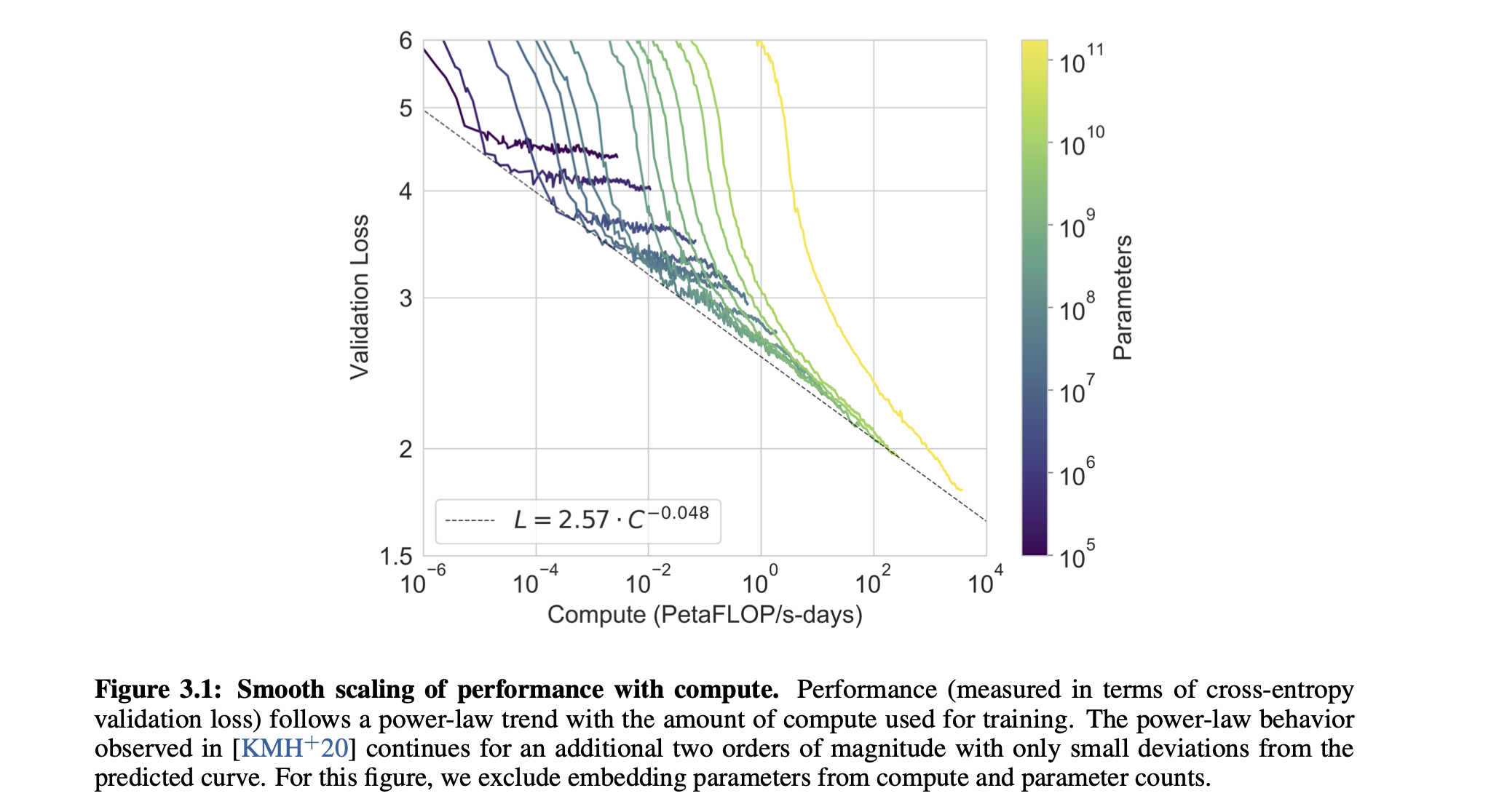
Scaling Law 的直观展现:横轴表示训练所使用的计算量;纵轴表示验证损失 (可以用来预测和表征模型在子任务上的精度和性能)。每一根线表示一个不同设置的模型。随着训练增加,计算量增加明显。你可以发现在损失和计算量之间有一个 Elbow 的地方,这就是最好的权衡点,可以理解为 一个不错的、又不用增加过多计算量的地方。把不同模型的权衡点连起来可以发现服从一个 Power Law 分布。
这个分布揭示一个问题。要想损失以线性水平持续提升,你的计算量、数据量必须以指数级别向上增。
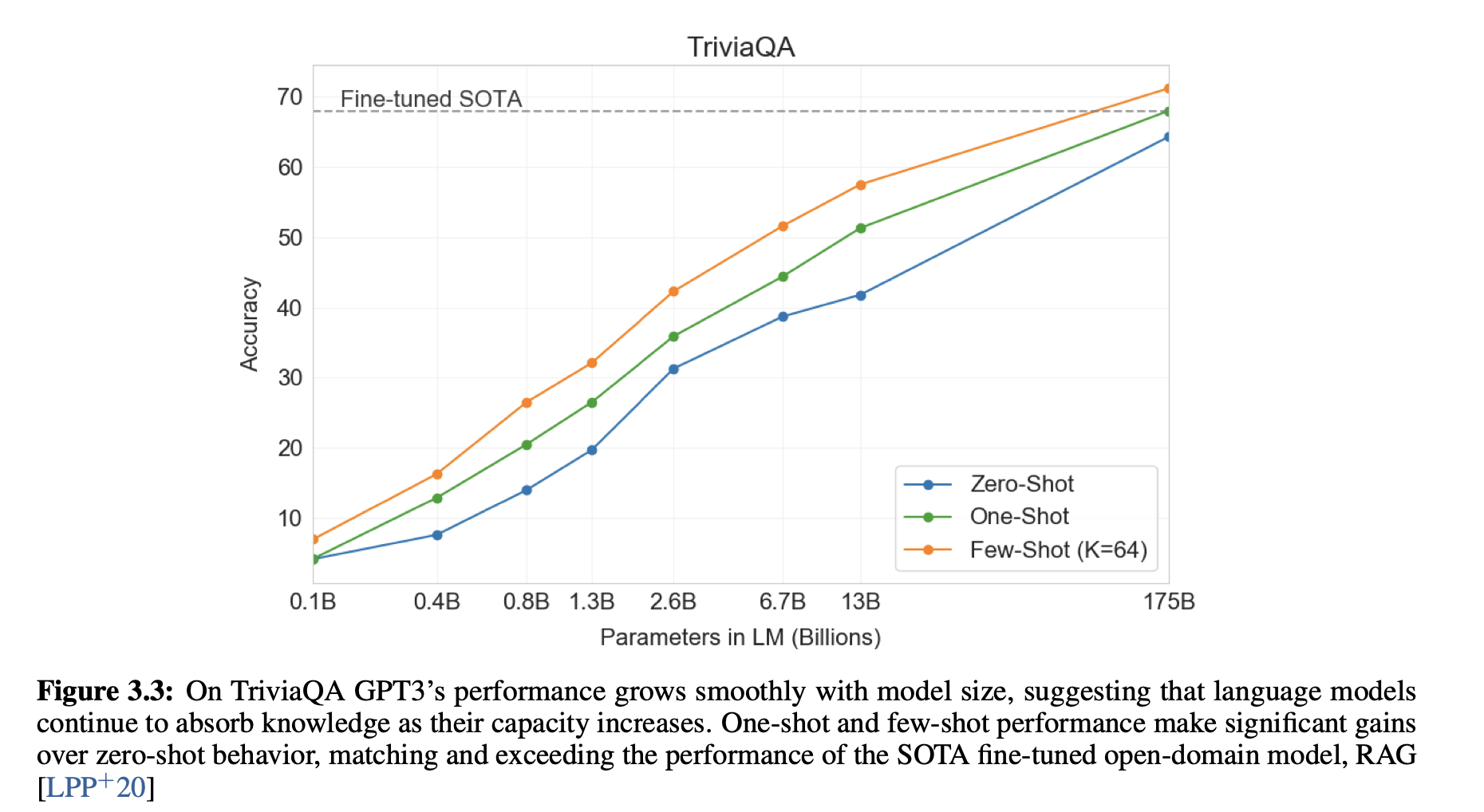
关于把模型搞大后,你的 Few Shot, Zero Shot 的结果甚至可以逼近原先 Fine Tune 过后的 SOTA。
当然文章是一个很详细的技术报告,一贯地放了很多结果和讨论,包括对LLM学习的讨论,究竟是学到了这些内容,还是仅仅从自己的记忆、数据库里找 到了对应的任务,找到一个相似的的结果反馈出来?
文章也提到这个东西是个庞大的黑盒。参数过于巨大,导致其实无法很好得知,哪些是关键的权重,为什么得到这样子的结果。
最后讨论了这种部署到生产环境的AI工具可能的影响。
-
半监督学习:有一些标号的数据,也有大量没有标好的数据,如何充分利用这些所有的数据进行学习。后来为了区分把GPT/Bert这类的训练也叫做自监督学习 (self-supervised learning). ↩