ResNet: 深度残差学习⚓︎
约 2426 个字 8 张图片 预计阅读时间 8 分钟 总阅读量 次
Deep Residual Learning for Image Recognition. 2015. Microsoft. arxiv.
残差学习的奠基之作。Kaiming He!
问题:深的神经网络很难训练。并且,一个问题是,深度卷积神经网络,只需要把层堆叠得越来越深就可以了么?可是如果堆叠得很深,那么很容易出现梯度消失和梯度爆炸。在当时,已经有一些缓解方法:Normalization, Initialization。 但是,依然有一个问题:层数多了,性能差了。
分析:进一步地,作者发现这并不是过拟合导致的。因为训练误差和测试误差都变高了(Overfitting:训练误差很低,测试误差很高)。这意味着,那些深的模型并没有训练到比较好的结果。
再进一步地解释,一个浅网络和一个它对应的深版本,如果浅网络效果还不错的话,深网络效果不应该变差。这是因为,深网络新加的层总可以学成一个Identity Mapping,也就是把权重学成 1/n,使的输入输出是对应的。比如一个 20 层网络和一个完全相同结构的 34 层网络,就算34层网络效果再差,它至少可以学成“前20层参数和浅网络相同,后14层只是简单地对结果做 mapping。
但是实际训练没有训练出这个结果。
所以,这篇文章的工作实际是:既然它训练不出来,我就构造一个Identity Mapping, 使得深的网络总不会变得比浅的网络更差。
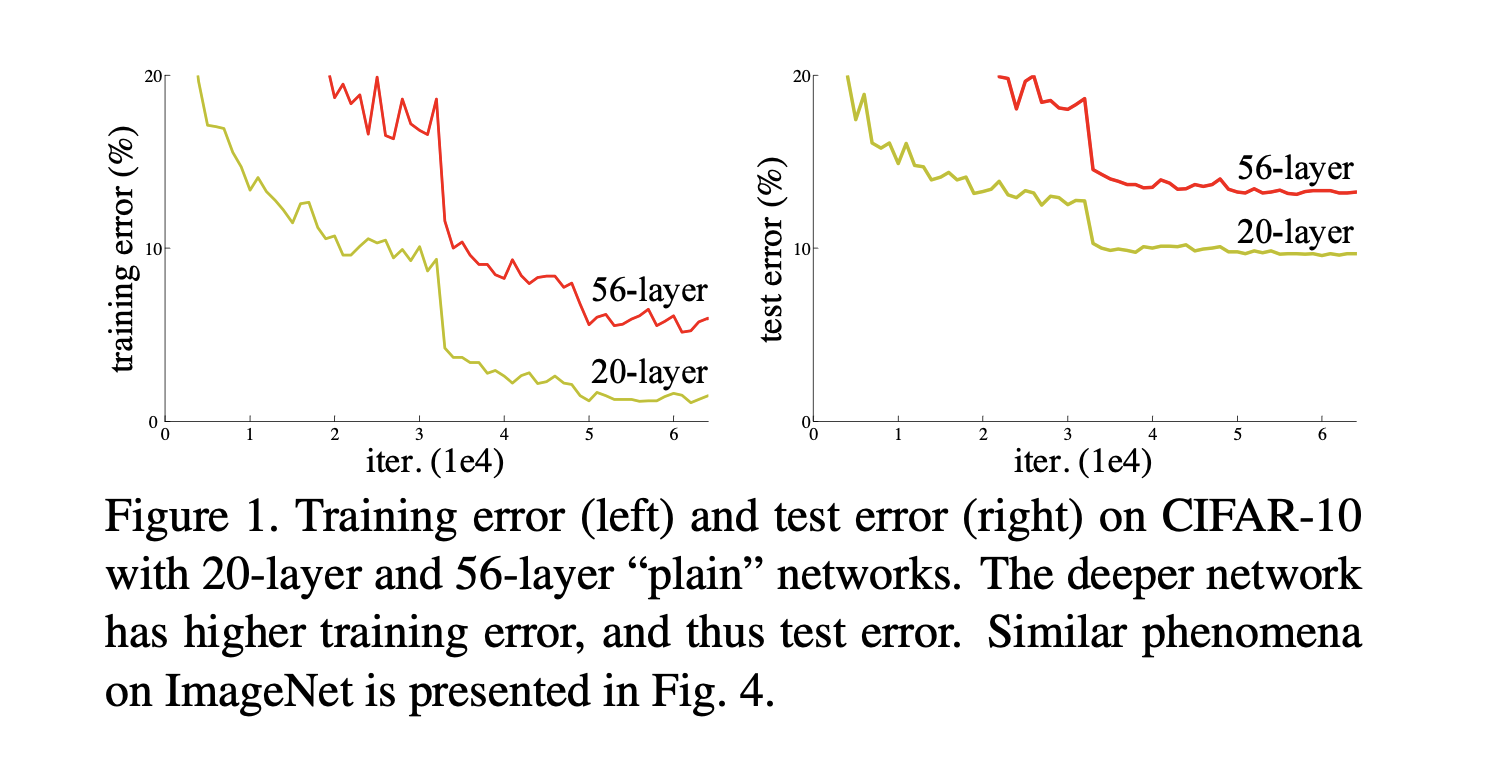
一个更深的网络(没有使用残差连接),其训练误差和测试误差均大于一个浅的网络。
解决思路:用残差学习的框架进行训练,能够比之前的网络深很多。
效果:实验表明可以训练8倍于VGG的深的网络。赢下了ImageNet竞赛。
解决思路⚓︎
在把神经网络堆叠得更高的时候,每一层学习的时候不只是学习上一层的输入,而是学的 \(H(x) - x\),也就是学习的是残差,在这一层输出的时候,把上一层的 \(x\) (作为 identity )再加上去,最后做 ReLU即可。一个小的 Block 如下图所示。
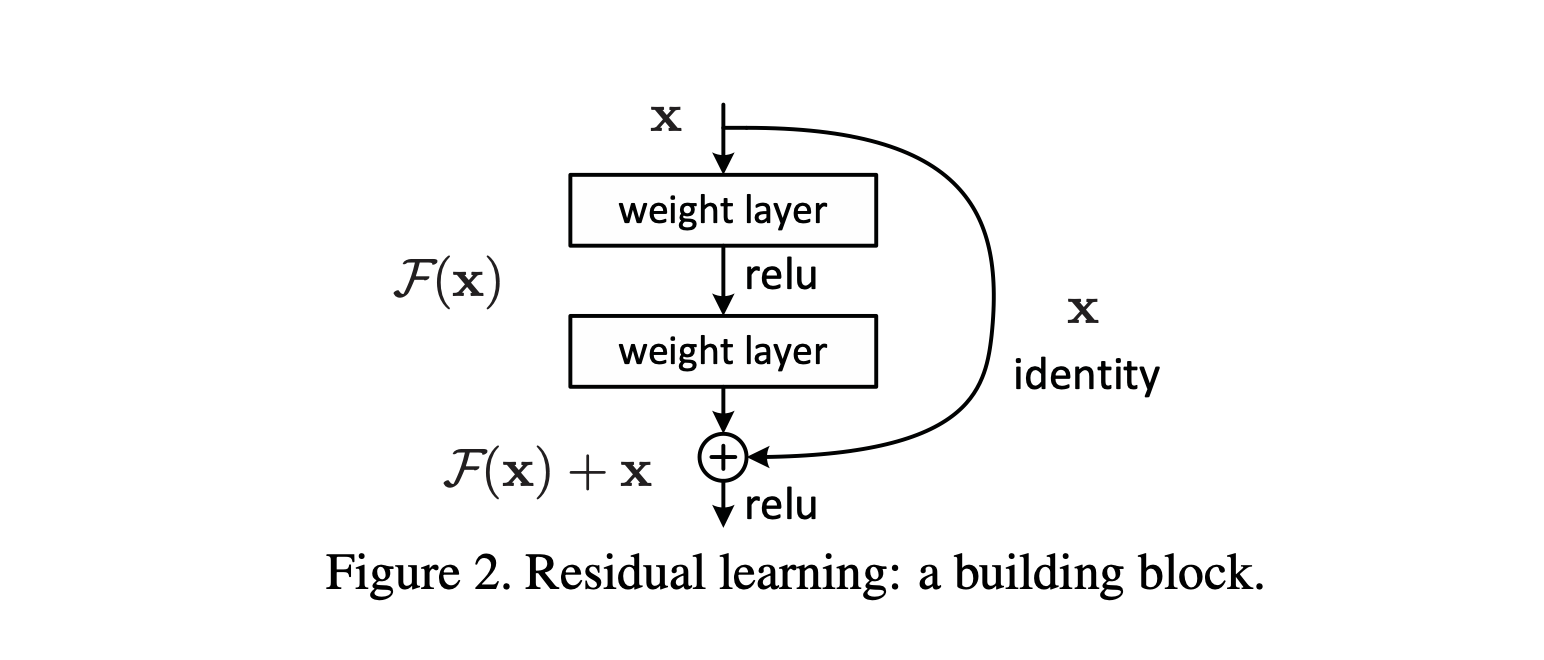
这种Shortcut的做法90年代的神经网络就有体现,它不增加复杂度、不增加模型的参数,并且十分易于实现。
处理输入和输出不同的情况⚓︎
- 添加额外的 0,把多出来的部分填充掉;
- 投影,即做如下操作:
\[\mathbf{y} = \mathcal{F}(\mathbf{x}, \{W_i\}) + W_s \mathbf{x}.\]
在ResNet中,当残差块的输入 \(\mathbf{x}\) 和残差函数 \(\mathcal{F}\) 的输出维度不相等时(例如因通道数改变、空间尺寸下采样等导致维度 mismatch),处理方式是在shortcut连接中引入线性投影\(W_s\),使其维度匹配后再进行元素相加。
具体来说: - 线性投影\(W_s\)可以是1×1卷积层(既可以调整通道数,也可通过设置步幅实现空间下采样),它对输入\(\mathbf{x}\)进行线性变换,将其维度调整为与\(\mathcal{F}(\mathbf{x}, \{W_i\})\)的输出维度一致。
空间维度不做处理,在channel维度做改变。
- 经过这样的处理,残差块的输出就可以表示为 \(\mathbf{y} = \mathcal{F}(\mathbf{x}, \{W_i\}) + W_s\mathbf{x}\),从而解决了维度不匹配时无法直接相加的问题。
当然,只有在需要维度匹配时才使用\(W_s\),否则优先使用恒等映射(即不进行投影,直接传递\(\mathbf{x}\)),这样既解决了维度问题,又不会额外增加过多参数和计算复杂度。
实现⚓︎
- 图片的短边随机采样到 \([256, 480]\) (随机切割的时候随机性更多一些);
- 颜色的增强:亮度、饱和度等的增强
- Batch Normalization;
- SGD, mini-batch: 256; learning rate: 0.1;
- decay, momentum.
10-crop testing
10-crop testing 是深度学习模型,特别是在图像分类任务中,一个非常经典且重要的测试阶段数据增强 方法。简单来说,10-crop testing 的核心思想是:对一张测试图片,生成10个不同的子区域(crops),让模型分别对这10个区域进行预测,然后综合这10个预测结果来决定图片的最终类别。它的主要目的是为了更准确、更稳定地评估模型的性能。
这样做可以避免因为图片中目标物体的位置、大小或拍摄角度等因素的偶然性,导致模型预测出现偏差,从而得到一个更鲁棒、更可靠的评估分数。
1. 生成 10 个裁剪区域 (Crops)
-
步骤 A:5个角落裁剪 + 中心裁剪
- 从一张输入图片中,我们先裁剪出 4个角落 和 1个中心 区域。
- 为了保证输入尺寸一致,这些裁剪区域的大小通常是原图的一部分(例如,在ImageNet上,原图缩放到短边为256后,裁剪出5个224x224的区域)。
-
步骤 B:水平翻转
- 将上述步骤中得到的 5个裁剪区域 分别进行水平翻转(镜像),从而得到另外5个区域。
-
总计:5个原始裁剪 + 5个水平翻转后的裁剪 = 10个裁剪区域。
2. 进行10次预测
将10个裁剪区域分别输入到已经训练好的模型中,模型输出10个预测结果;
3. 融合预测结果
最后,我们将这10个预测结果融合起来,得到一张图片的最终预测。最常用的融合方法是:
- 取平均值:将这10个预测的概率向量按元素求平均,然后取平均概率最大的类别作为最终结果。这是最常用、最有效的方法。
Bottleneck⚓︎
做到更深的层时,引入 Bottleneck design。因为深的时候,我们可以学习到更多的图片特征,因此图片大小可以放大一些。但是,此时计算量会随着图片尺寸平方增长。作者就提出了 Bottleneck 做法。
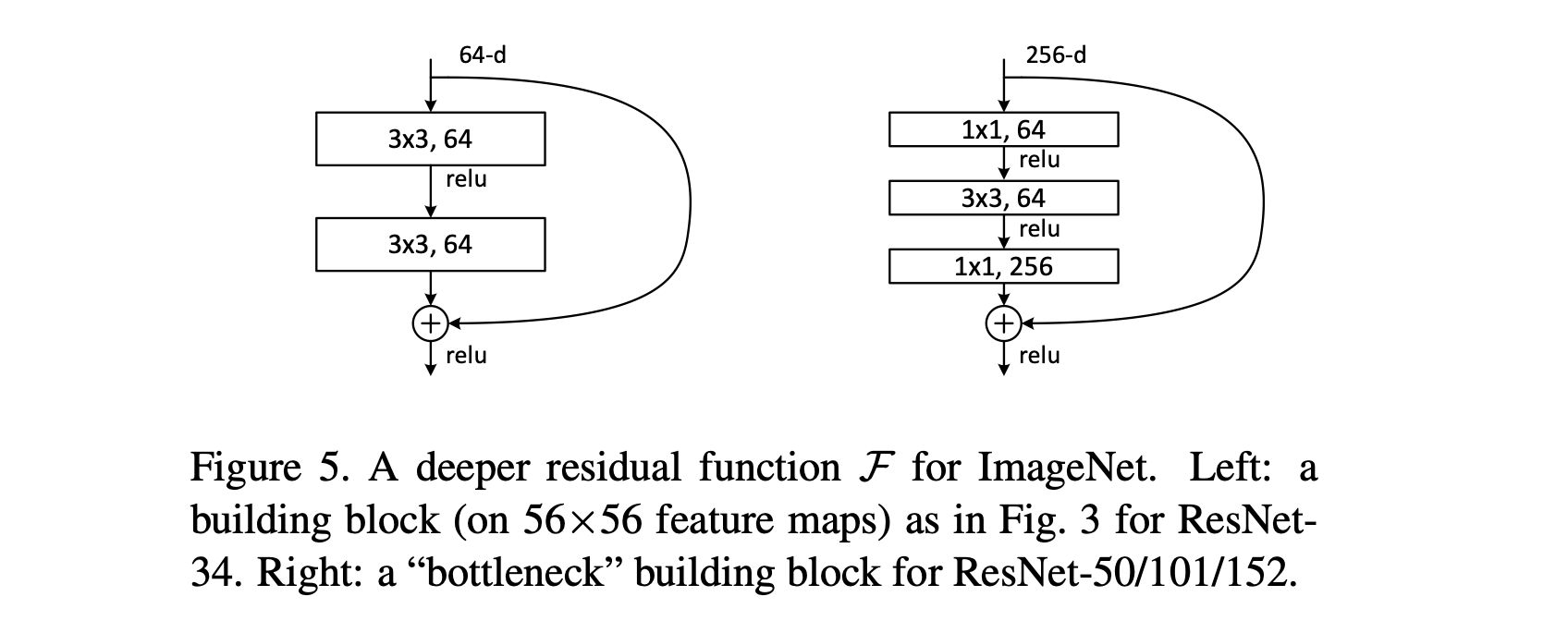
以ResNet-50中的一个块为例(假设输入是256维通道):
-
1x1 卷积(降维):
- 卷积核:1x1,数量:64个
- 作用:将输入的256维通道压缩(降维) 到64维。
- 这一层只改变通道数,不改变特征图的空间尺寸(高和宽)。
-
3x3 卷积(核心卷积):
- 卷积核:3x3,数量:64个
- 作用:在低维空间(64维) 进行标准的空间卷积,提取特征。这是整个块的核心计算。
- 通常会使用Padding=1来保持特征图尺寸不变。
-
1x1 卷积(升维/还原):
- 卷积核:1x1,数量:256个
- 作用:将64维的通道数扩展(升维) 回256维,以便与shortcut连接过来的原始输入(256维)进行相加操作。
所以,一个Bottleneck块的数据流是:256维 -> (1x1卷积) -> 64维 -> (3x3卷积) -> 64维 -> (1x1卷积) -> 256维。
Bottleneck最根本的目的是为了在加深网络的同时,极大地降低模型的复杂度和计算成本。
对比:没有Bottleneck的“直筒”结构
一个残差块,输入输出都是256维。如果没有Bottleneck,一个直观的想法是用两个3x3卷积层:
256维 -> (3x3卷积) -> 256维 -> (3x3卷积) -> 256维
我们来计算一下这个“直筒”结构的参数量(忽略偏置项):
* 第一层3x3卷积参数量:3 * 3 * 256 * 256 = 589,824
* 第二层3x3卷积参数量:3 * 3 * 256 * 256 = 589,824
* 总参数量:约118万
计算:使用Bottleneck结构
同样是输入输出256维,Bottleneck结构的参数量:
* 第一层1x1卷积(降维):1 * 1 * 256 * 64 = 16,384
* 第二层3x3卷积(核心):3 * 3 * 64 * 64 = 36,864
* 第三层1x1卷积(升维):1 * 1 * 64 * 256 = 16,384
* 总参数量:16,384 + 36,864 + 16,384 = 69,632
- 直筒结构参数量: ~1,180,000
- Bottleneck参数量: ~70,000
- Bottleneck将参数量减少到了原来的约1/17
现在答案就很清晰了:
-
第一个1x1卷积(降维)的作用:
- 核心目的:创建一个“计算瓶颈”。在进入计算代价高昂的3x3卷积之前,先用1x1卷积把通道数大幅降低。这样,最耗时的3x3卷积操作是在一个非常低的维度(如64维)上进行的。
-
最后一个1x1卷积(升维)的作用:
- 核心目的:将维度还原,以匹配shortcut路径。残差学习要求残差块(F(x))的输出维度必须与shortcut连接(x)的维度相同,才能进行逐元素相加(
H(x) = F(x) + x)。因此,在完成核心的3x3卷积后,需要再用一个1x1卷积将通道数扩展回原始的维度。
- 核心目的:将维度还原,以匹配shortcut路径。残差学习要求残差块(F(x))的输出维度必须与shortcut连接(x)的维度相同,才能进行逐元素相加(
最终效果:Bottleneck结构使得构建像ResNet-152这样极深的网络在计算上成为可能,它既保留了网络的表达能力(通过3x3卷积),又聪明地规避了参数和计算量的爆炸式增长,是深度学习模型设计中“用更少的钱,办更多的事”的典范。
架构⚓︎
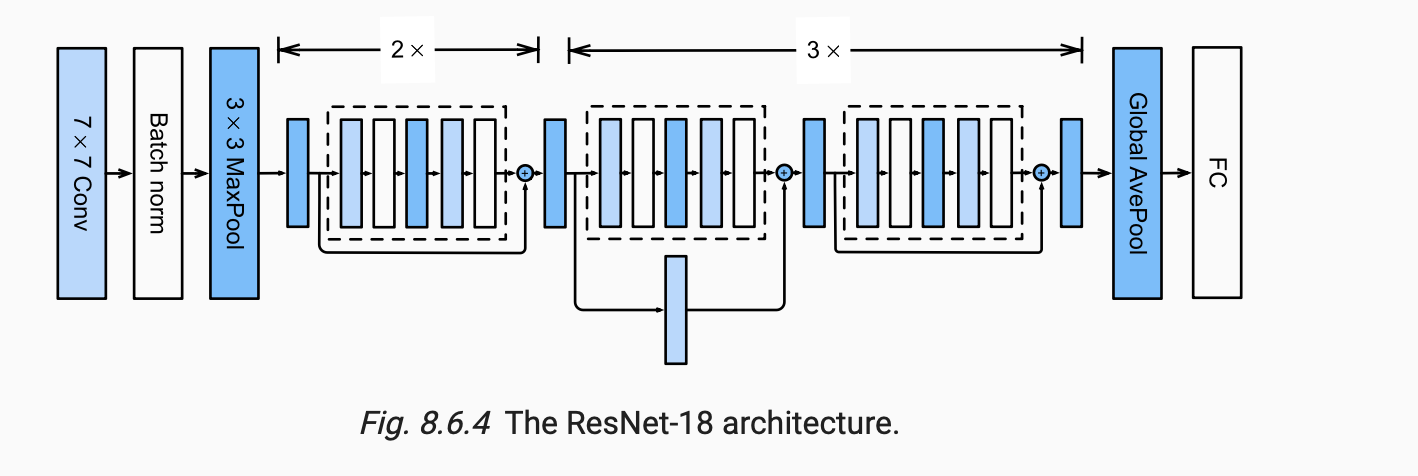
(Links)
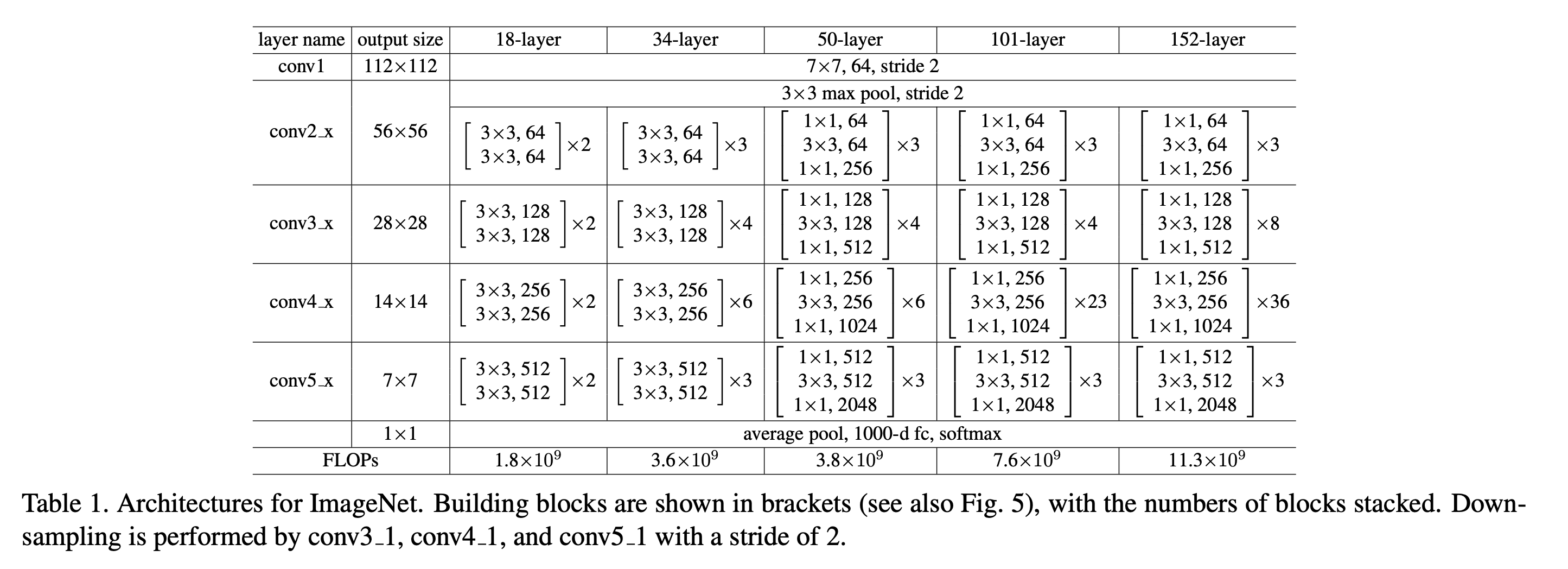
Architecture
有一些残差连接是虚线,表示做了升维,比如 256 -> 512 Channel 等。
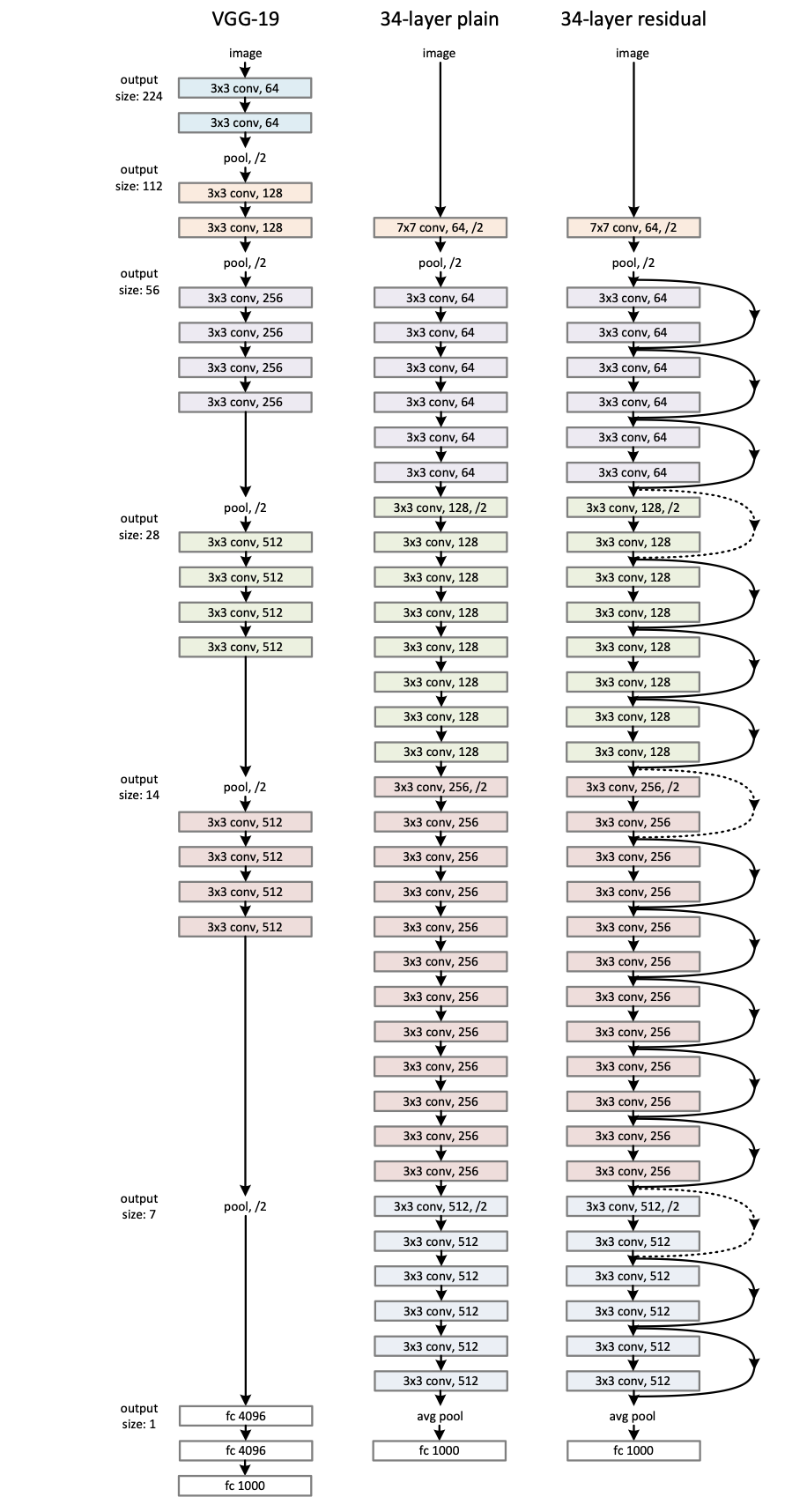
效果⚓︎
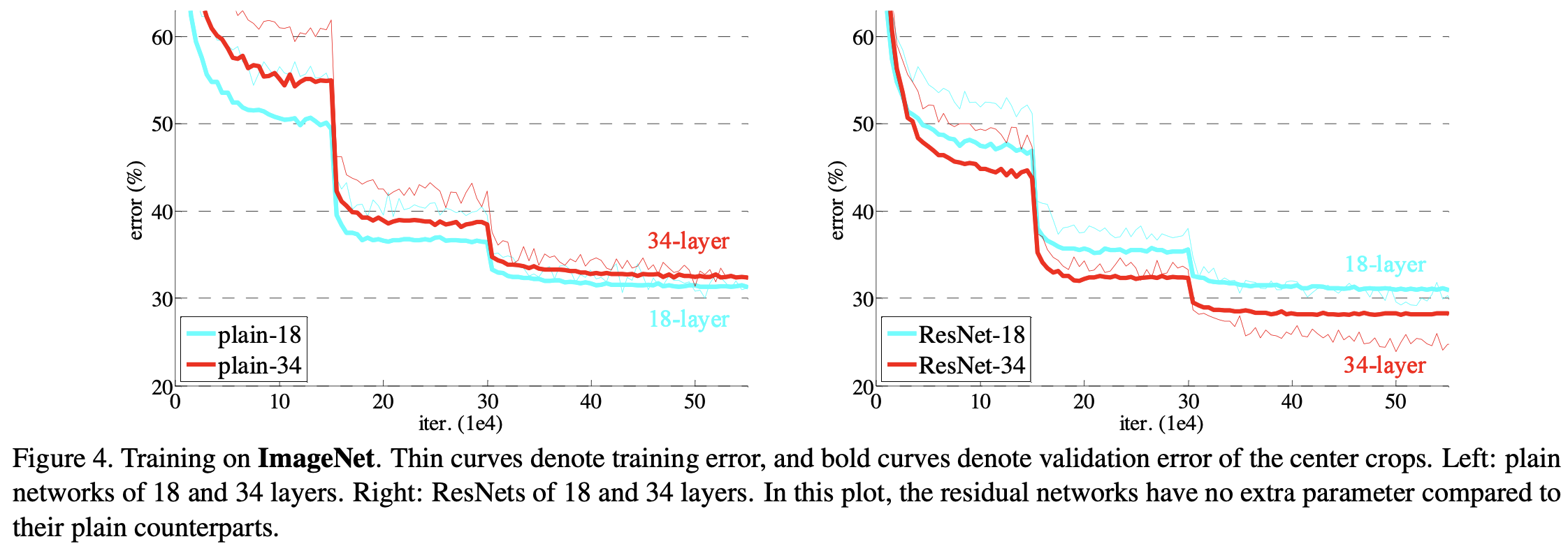
中间的突变是学习率下降带来的。可以看到加了 Residual Connection 之后,ResNet 34 的 Error更小了,相比先前提升幅度也更加明显了。
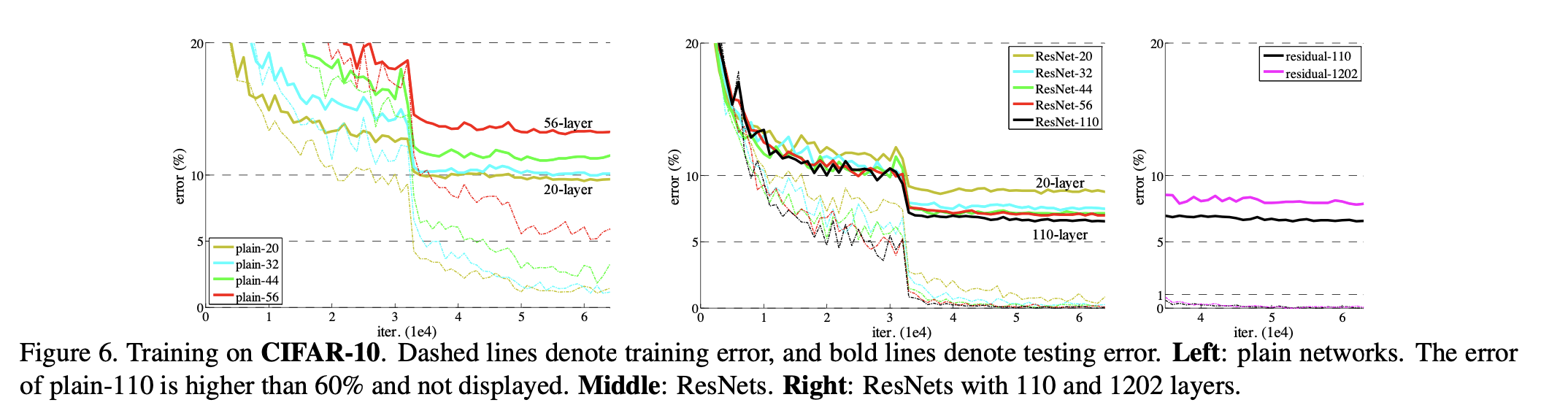
在 CIFAR 设计并训练了更深的 ( > 1000 层) 的神经网络。
后续⚓︎
ResNeXt: 分组卷积,类似一个“多头”的处理机制。 Split-Transform-Merge 的操作。