关于 Transformer 的细节⚓︎
约 432 个字 1 张图片 预计阅读时间 1 分钟 总阅读量 次
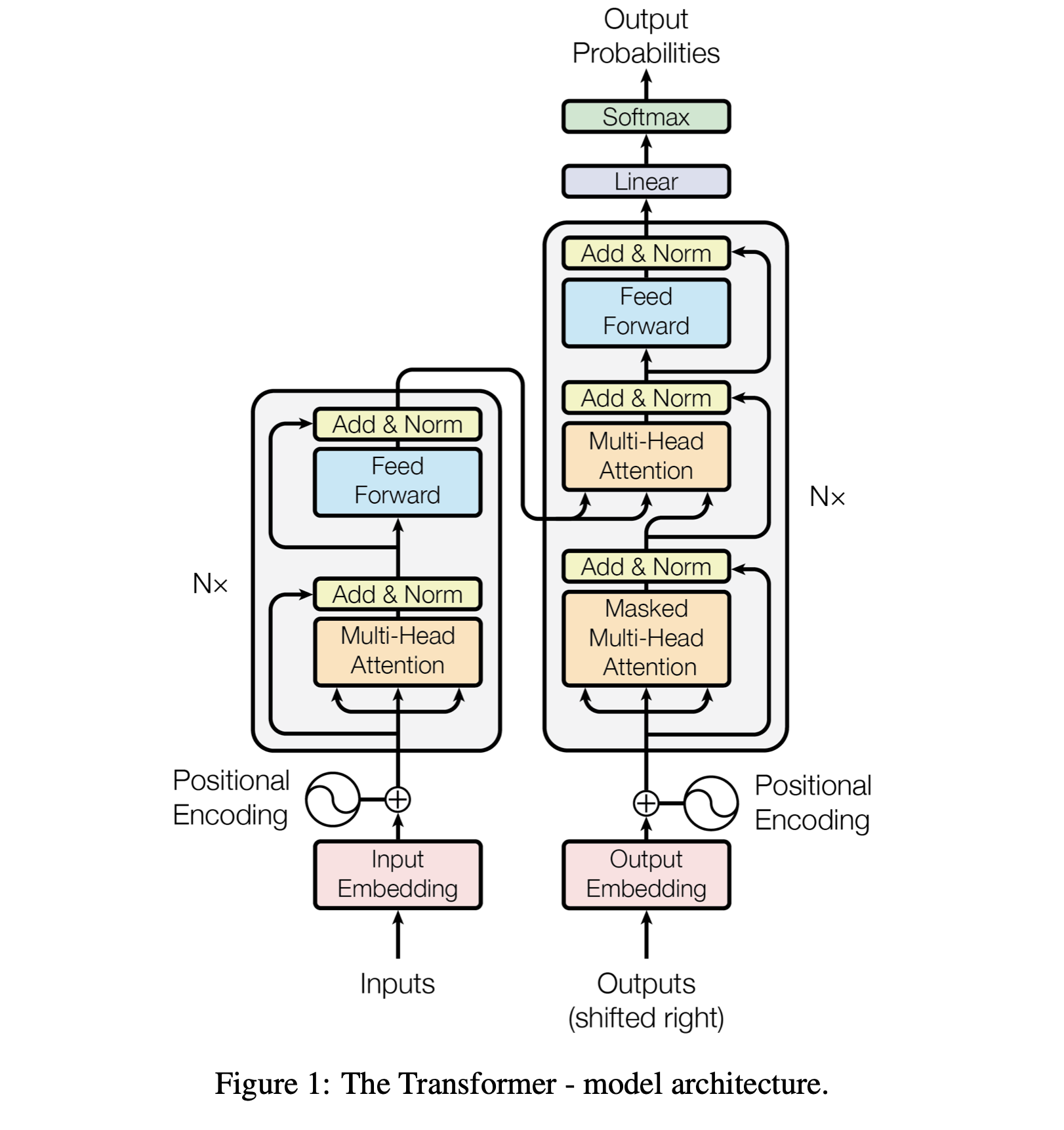
如何计算 Encoder/Decoder 块的参数量⚓︎
词嵌入 (embedding)
本质上是一个矩阵。 输入是字典的大小 (\(V\))。输出为隐藏层大小 (\(H\))。 即 \(V \times H\) 的矩阵。 输出的结果进入 Transformer 块。
Transformer 块实际上有俩主要部分:Attention Block 和 FFN Block。
注意力机制
Q, K, V 分别投影。最后会有一个合并的 O 矩阵。多头对参数量没有影响1。此时每个矩阵都是 \(H \times H\) 的大小。故有 \(4 H^2\) 个参数。
FFN (其实是一个 MLP ):
两层全连接,第一层会把 Attention 层输出的结果放大到 \(4H\),第二层会把第一层的结果缩放回 \(H\)。 所以有一个 \(H \times 4H\) 和一个 \(4H \times H\) 的矩阵。合起来参数量 \(8 H^2\)。可以发现其实 FFN默不作声地贡献了超级多的参数量。
所以一个 Transformer 块里的参数量是 \(12 H^2\),我们考虑一个有 L 个Transformer 块的模型,此时总参数量 \(12 H^2 L\)
我们把上面的合起来!
总参数量大致为:
\[VH + 12 H^2 L\]
其中 \(V\) 是词典大小,\(H\) 是隐藏层大小,\(L\) 是堆叠的 Transformer 块(具体而言是一个Encoder/Decoder块)的数量。
当然,有一些细节的地方其实没考虑:
- 比如每次做 Layer Norm 层的时候也是有参数的(只不过相比于其他组件,已经不是一个数量级的了),由于是对特征的初始化,并且需要学习 \(\gamma, \beta\) 两个参数,所以为 \(2 \times (H + H)\)
- 比如有的模型每次输出映射到词表时,还需要一个映射矩阵,那又是一个 \(VH\) 大小的矩阵。
-
我们不考虑头的情况,因为头本身只是切分了隐藏层,没有改变参数量。 ↩