Ollama在本地运行大语言模型⚓︎
约 735 个字 4 行代码 3 张图片 预计阅读时间 2 分钟 总阅读量 次
2025.09.28 本部分的内容会尽快迁移至人工智能模块。
Ollama是一个允许您在本地运行开源大型语言模型的强大框架。
目前支持许多很新很好用的开源大模型。前不久推出的Gemma也支持了,传统的Llama2,Mistral-7B等早就可以使用。并且提供多种参数规模的供下载。使用前,Ollama将模型权重、配置和数据捆绑到一个由Modelfile定义的包中,优化了包括GPU使用等设置和配置细节。
更重要的是,继承开源精神,很好上手。反馈很快。
安装与使用⚓︎
首先去ollama点com官网下载软件到你的平台上。目前支持macOS(必须big sur以上版本)/Linux,不过在Windows系统上只有预览版(Preview)。
也可以在终端进行下载:
安装好后,打开终端,这里以macOS系统安装llama2为例。输入命令:
此时会自动拉取模型并下载。等待10min左右,安装完成,显示如下:
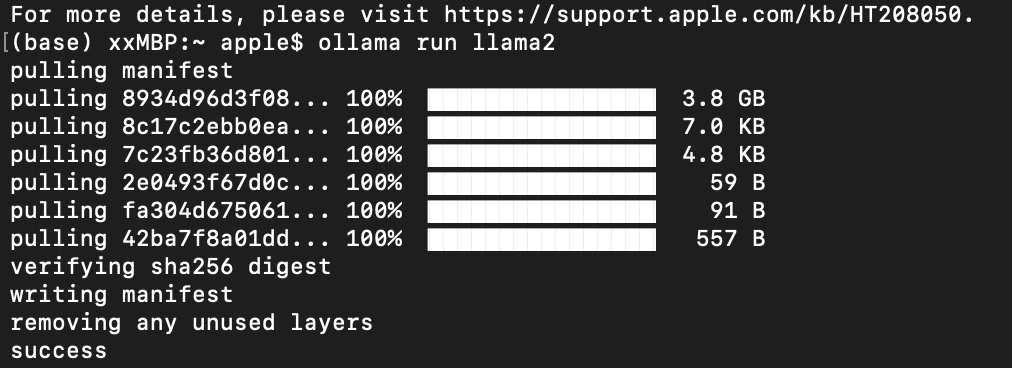
出现success就说明已经安装好了。其实类似的开源模型都可以通过同样方式安装好。没有下载的会自动给你下载,然后开始运行。
这里Ollama提供了保存和加载对话的功能。在输入框进行如下指令,可以加载、保存和显示模型信息。
| 命令 | 含义 |
|---|---|
/show |
展示模型信息 |
/load <model> |
加载对话或者模型 |
/save <model> |
保存当前对话 |
/bye |
退出 |
/?, /help |
弹出帮助 |
/? shortcuts |
更多键盘快捷键 |
下面是一些对话实例:
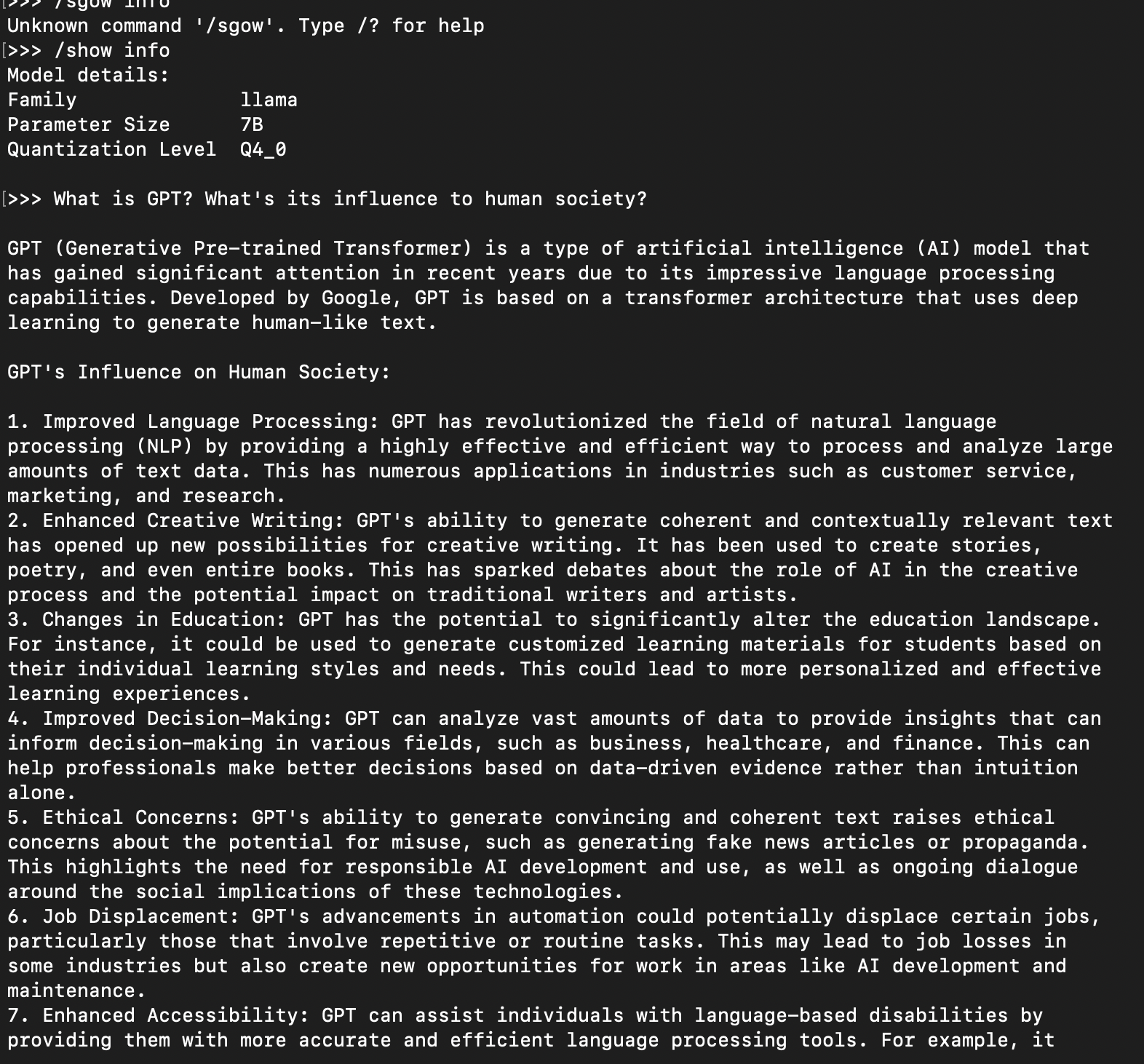
我用的是7B的Llama-2。在本地跑生成速度还是很快的。
一些注意事项⚓︎
运行不同参数量的模型,所需要的电脑内存不同。Ollama针对提供的每个模型给出了相关硬件需求、上下文等。
-
7b 大小的模型通常至少需要 8GB 的 RAM
-
13b 大小的模型通常至少需要 16GB 的 RAM
-
70b 大小的模型通常需要至少 64GB 的 RAM
在 macOS 下,模型将下载到 ~/.ollama/models 路径中。
默认情况下,Ollama 使用 4 位量化(Quantization)。要尝试其他量化级别,需要设置标签。q 后面的数字表示用于量化的位数(即 q4 表示 4 位量化)。数字越大,模型越准确,但运行速度越慢,需要的内存就越多。
如果有多个版本的模型,默认会下载参数量最小/最新的那个。
比如你机器硬件达标,下载70b的Llama-2,就需要指明下载的版本:
下面是一些模型和下载指令:
| 模型 | 指令 |
|---|---|
| llama-2 latest | ollama run llama2 |
| llama-2 13b | ollama run llama2:chat |
| Gemma | ollama run gemma |
| Mistral latest | ollama run mistral |
| llava-13b | ollama run llava:13b |
| codellama | ollama run codellama |
| Vicuna | ollama run vicuna |
完整的可以在官网这里找到。