在Jupyter 中美化 Pandas 表格⚓︎
约 1312 个字 98 行代码 12 张图片 预计阅读时间 6 分钟 总阅读量 次
⚠️ 本笔记所有内容均需在Jupyter Notebook 或者 Jupyter Lab中运行才能取得理想的展示效果。
在数据科学应用中,Jupyter Notebook + Pandas已经成为一套很成熟的处理流程。Jupyter提供了在不同代码块中处理数据并可视化的方法。但是,如果我们需要展示的表格数据很多,我们想要将一些关键的数据进行高亮、突出展示,或者把一些“效果不好”、“不想要展示出来”的数据隐藏或者虚化处理,我们该怎么做呢?
实际上,pandas通过Style函数,提供了很多灵活易用的处理方法。本笔记就是摘取了一部分方法进行展示。参考链接:pandas official docs, table visualization.
数值格式化⚓︎
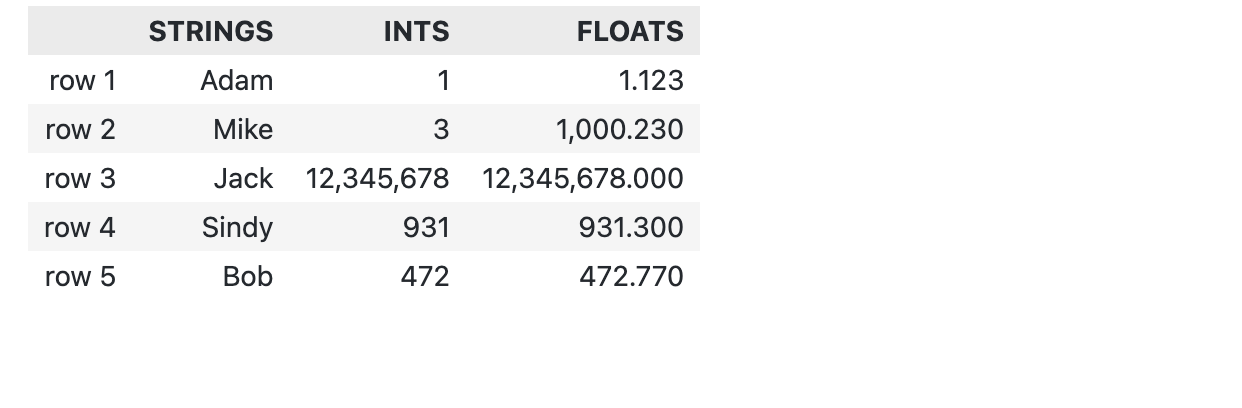
应用场景:对一些较大的数字,比如1100000,为了方便观看和工整,需要在表格里对这个数字的千分位、百万分位等用逗号 , 分隔开。写成: 1,100,000。 同样地,pandas也可以对小数点的样式进行标记,并且设置保留小数的位数。此时可以用以下方式:
import pandas as pd
import numpy as np
import matplotlib as mpl
df = pd.DataFrame({
"strings": ["Adam", "Mike", "Jack", "Sindy", 'Bob'],
"ints": [1, 3, 12345678, 931, 472],
"floats": [1.123, 1000.23,12345678, 931.3, 472.77] })
df.style \
.format(precision=3, thousands=",", decimal=".")\
.format_index(str.upper, axis=1)\
.relabel_index(["row 1", "row 2", "row 3", 'row 4', 'row 5'], axis=0)
隐藏一部分数据⚓︎
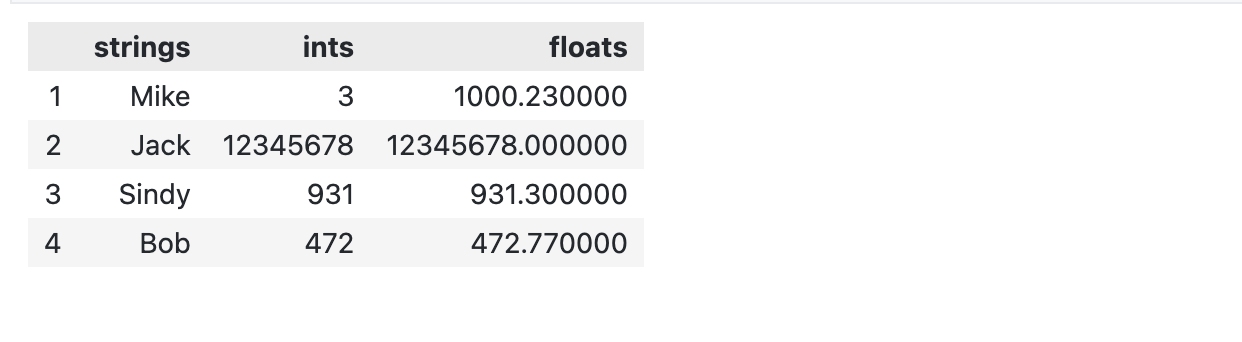
如果有的表格的行/列数比较多,我们又不想删掉这些列,但是想在展示的时候隐藏它们,此时可以通过设置 style 来隐藏一些列/行。这不会修改本来表格里的数据。
比如如下代码就会隐藏原来表格的第一行。
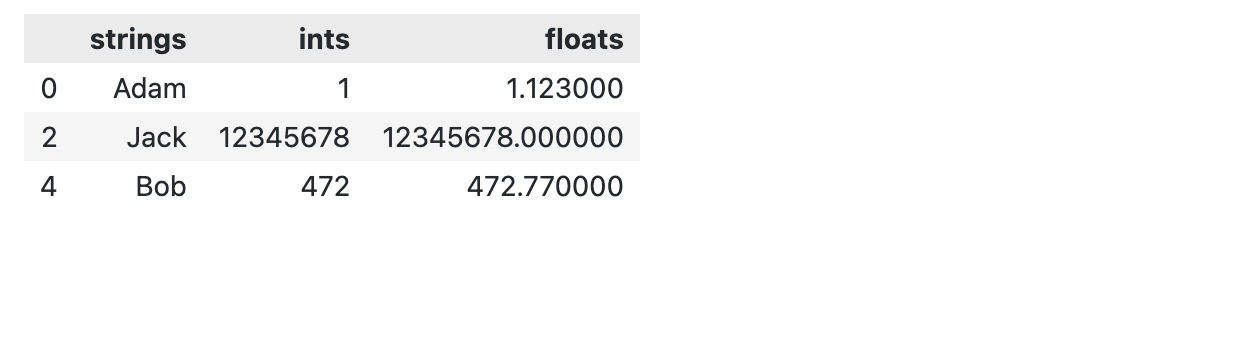
一般而言,我们会通过某个函数来罗列想要隐藏 / 展示的行。比如:
连接两个DataFrame的结果⚓︎
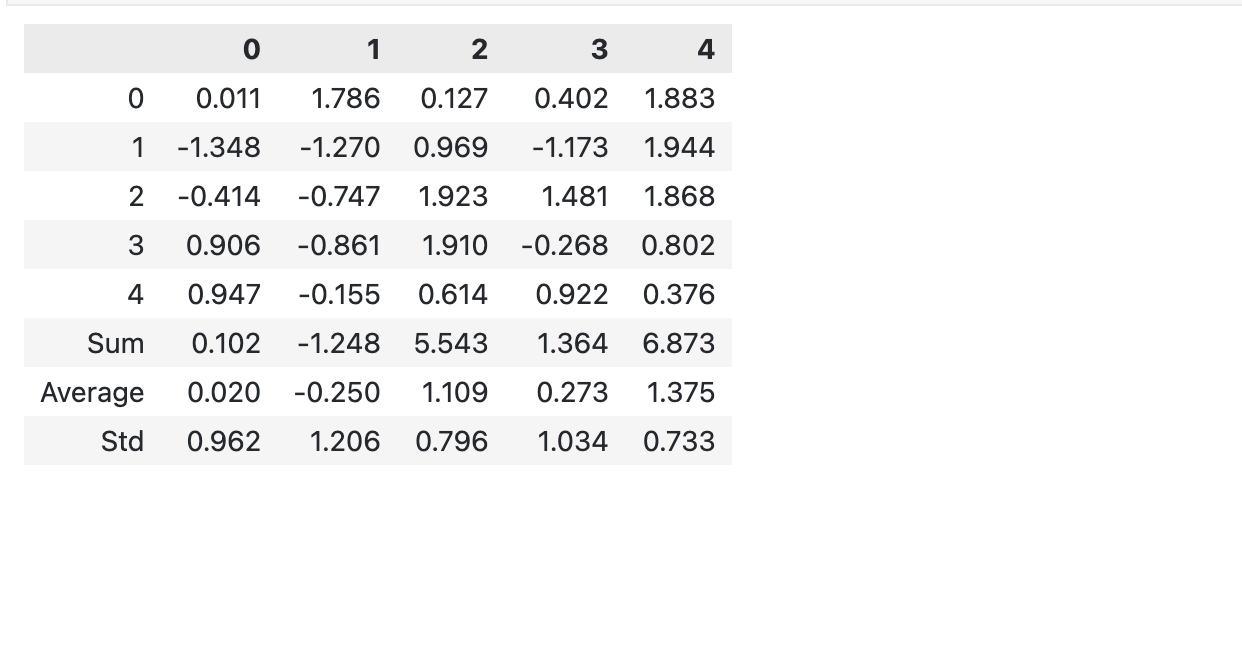
对应 concatenate 操作。如果两个表有相同的列,那么可以用 agg 来计算原始数据的一些指标,比如均值、方差、最大值、最小值、标准差,然后接在原始表的后面展示出来,与此同时还不改变原来表的数据。
比如下面的代码,先生成了一个随机的5x5的表格,然后计算了每列的均值、方差和标准差,最后把这三列接在原来的表格后面。
df = pd.DataFrame(np.random.randn(5, 5))
summary_styler = df.agg(["sum", "mean", 'std']).style \
.format(precision=3) \
.relabel_index(["Sum", "Average", 'Std'])
df.style.format(precision=3).concat(summary_styler)
对数据进行操作⚓︎
pandas 也提供了灵活的方法,对给定列表中的某些数据进行处理后,按照相应条件赋予相应的style格式。主要是两个。
map() : 传入一个值(single value),返回一个带有CSS属性的样式对;
apply(): 传入一个 DataFrame / Series,返回一个相同大小的Series, DataFrame, 甚至是 numpy.array。该方法会一次性地对DataFrame的行/列进行某些处理。
类似pandas,通过设置 axis = 0/1 区分是选择行还是列。
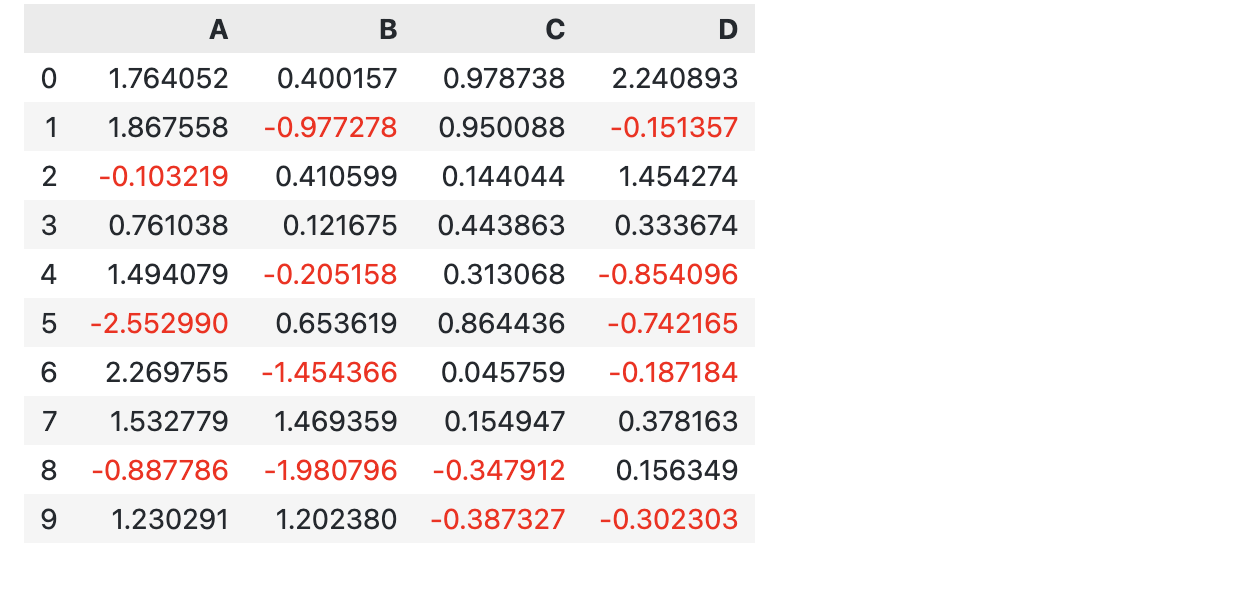
比如下面的代码。将所有小于0的元素标记为红色。
np.random.seed(0)
df2 = pd.DataFrame(np.random.randn(10, 4), columns=["A", "B", "C", "D"])
def style_negative(v, props = ''):
return props if v < 0 else ''
s2 = df2.style.map(style_negative, props = 'color:red')
s2
高亮某一列的最大值,同时加粗某区间内值⚓︎
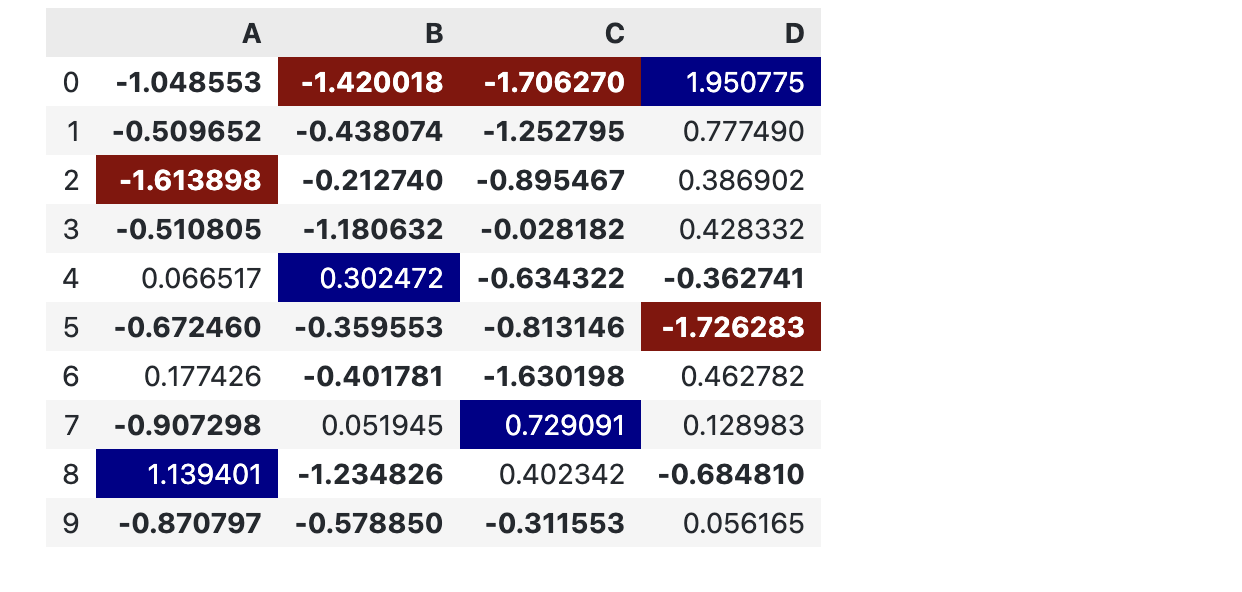
如果我们想看一眼每一列的最大或者最小值,可以先用numpy获取最大/最小元素的下标,然后设置在这个下标处赋予一个特定的CSS样式,这样就可以一眼看到最大和最小值。
这里我们可以把 map() 和 apply() 结合起来使用。
df2 = pd.DataFrame(np.random.randn(10, 4), columns=["A", "B", "C", "D"])
def highlight_max(s, props = ''):
return np.where(s == np.nanmax(s.values), props, '')
def highlight_min(s, props = ''):
return np.where(s == np.nanmin(s.values), props, '')
s2 = df2.style.map(style_negative, props = 'font-weight:bold;')\
.map(lambda v: 'opacity: 20%,' if (v < 0.1) and (v > -0.1) else None)
# 把所有 [-0.1, 0.1] 之间的值的opacity为20%
s2.apply(highlight_max, props = 'color:white;background-color:darkblue', axis = 0)
s2.apply(highlight_min, props = 'color:white;background-color:darkred', axis = 0)
如果想要对每一列的操作改成对行的,那么只需要调整 axis = 1 即可。
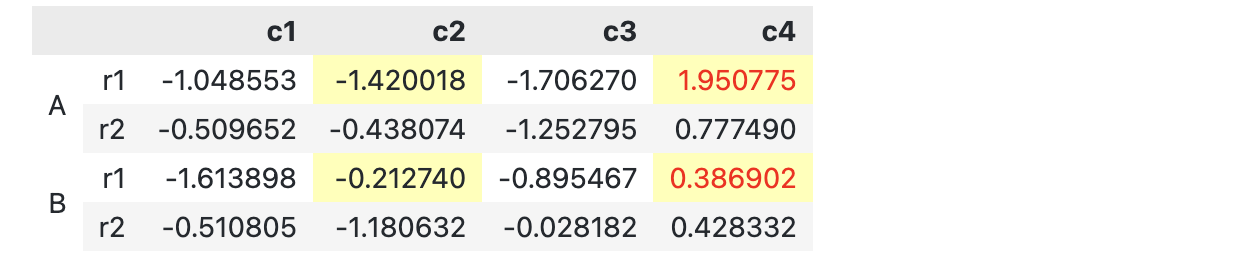
同时,我们可以灵活地用索引切片函数(IndexSlice)选取特定的行/列。比如下面的代码,我们只对 A 和 D 索引的c2, c4列进行最大值高亮,其他的行都不做修改。
import pandas as pd
import numpy as np
df3 = pd.DataFrame(np.random.randn(12, 4),
pd.MultiIndex.from_product(
[['A', 'B', 'C', 'D', 'E', 'F'],
['r1', 'r2']]),
columns = ['c1', 'c2', 'c3', 'c4'])
def highlight_max(s, props = ''):
return np.where(s == np.nanmax(s.values), props, '')
style_df3 = df3.style
for _ , tag in enumerate(['A', 'D']):
slice_ = pd.IndexSlice[tag, ['c2', 'c4']]
style_df3 = style_df3.apply(highlight_max, subset = slice_, axis = 0, props = 'color:red')
style_df3

对列名/行名进行美化⚓︎
除了对表格内的数字设置样式之外,还可以对列名、行名进行美化。比如:
map_index() 可以接收一个值,返回对这个值的CSS属性对;
apply_index() 可以接收一个函数。可以给这个函数输入一个序列,函数会返回一个Series或者numpy array,具有相同的长度,同时带有CSS属性。和前面类似,可以用 axis = 0/1 来区分是行还是列。
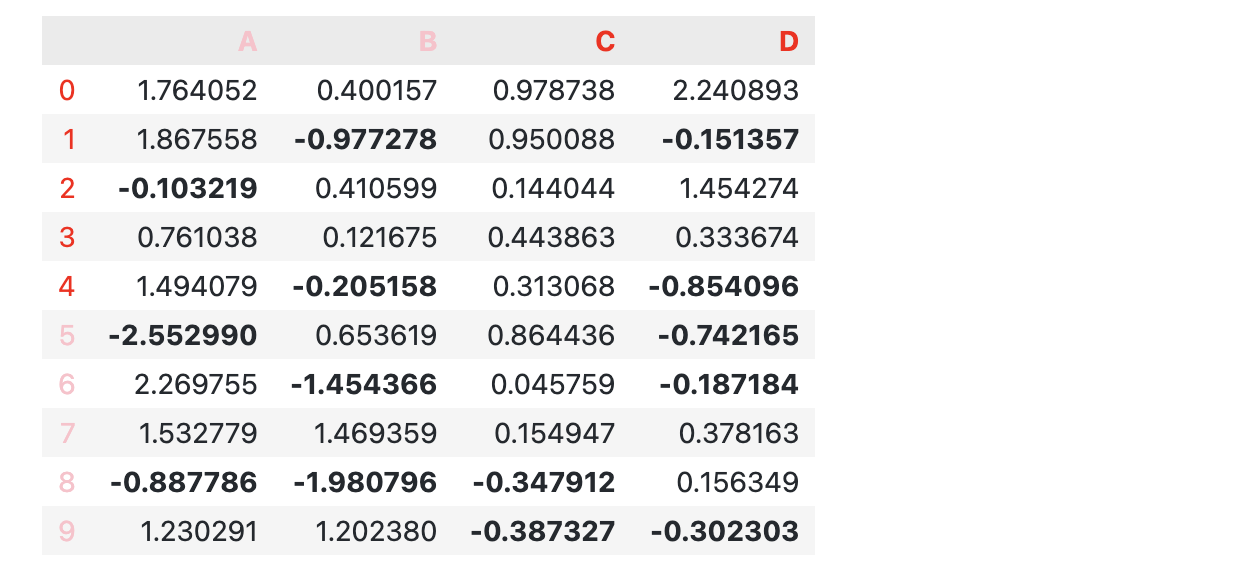
比如下面的代码就实现了按照一定规则对列/行名设置不同的颜色:对于前5行,行名标为红色,对于 A, B 列,列名标为粉色。
import numpy as np
import pandas as pd
np.random.seed(0)
df2 = pd.DataFrame(np.random.randn(10, 4), columns = ['A', 'B', 'C', 'D'])
s2 = df2.style.map(style_negative, props = 'font-weight:bold;')\
.map(lambda v: 'opacity: 20%,' if (v < 0.1) and (v > -0.1) else None)
s2.map_index(lambda v: 'color:pink;' if v > 4 else 'color:red', axis = 0)
s2.apply_index(lambda s: np.where(s.isin(['A', 'B']), 'color:pink;', 'color:red;') ,axis = 1)
设置表格名称⚓︎
就像一个可交换图表一样,pandas同样提供了进行交互展示的方法,鼠标悬停等可以呈现不同的效果。对于数据较多的情况是很合适的。
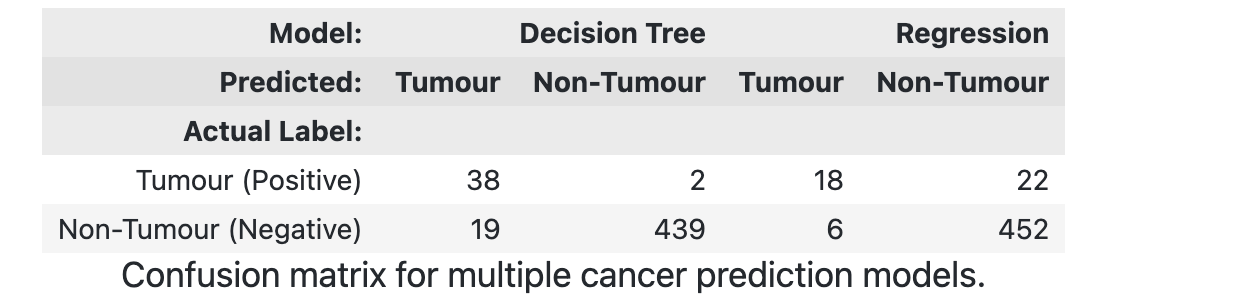
比如下面的表,我们设置了一个名称为 Confusion matrix for multiple cancer prediction models.
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index = pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns = pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:',
'Predicted:']))
s = df.style.format('{:.0f}').hide([('Random', 'Tumour'), ('Random', 'Non-Tumour')], axis = 'columns')
s.set_caption("Confusion matrix for multiple cancer prediction models.") \
.set_table_styles([{
'selector': 'caption',
'props': 'caption-side: bottom; font-size: 1.25em;'
}], overwrite=False)
借助subset函数进行数据切片操作⚓︎
前面提到用 map() 和 apply() 对函数进行操作,现在我们针对多个索引表格,利用 subset() 方法进行美化。比如如果我们想要高亮某些列,同时给某些元素不同的颜色,保持其他列不变。
df3 = pd.DataFrame(np.random.randn(4,4),
pd.MultiIndex.from_product([['A', 'B'], ['r1', 'r2']]),
columns=['c1','c2','c3','c4'])
df3
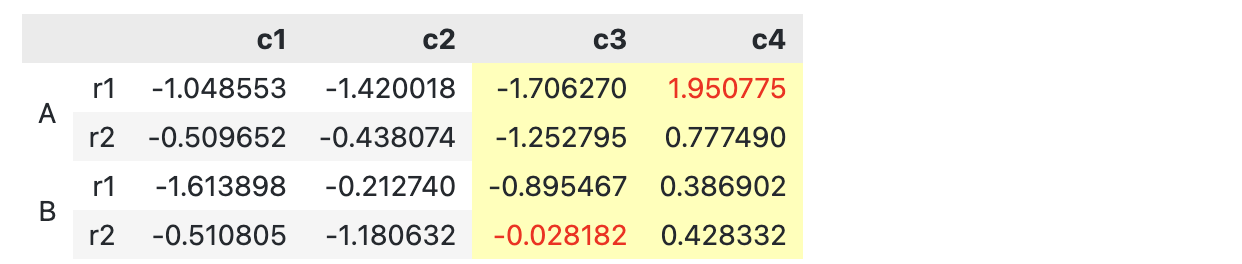
slice_ = ['c3', 'c4']
df3.style.apply(highlight_max, props='color:red;', axis=0, subset=slice_)\
.set_properties(**{'background-color': '#ffffb3'}, subset=slice_)
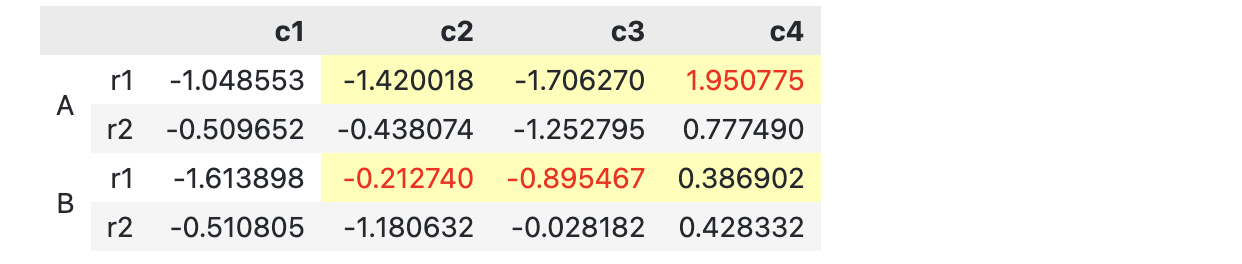
此外,我们也可以对行进行同样的切片操作,从而高亮的部分更加灵活了。
idx = pd.IndexSlice
slice_ = idx[idx[:,'r1'], idx['c2':'c4']]
df3.style.apply(highlight_max, props='color:red;', axis=0, subset=slice_)\
.set_properties(**{'background-color': '#ffffb3'}, subset=slice_)
切片操作也支持条件筛选(Conditional filtering),比如说,只有在第一列和第三列的和 < -2 的时候,高亮第2列和第4列的最大值。
slice_ = idx[idx[(df3['c1'] + df3['c3']) < -2.0], ['c2', 'c4']]
df3.style.apply(
highlight_max,
props='color:red;',
axis=1, subset=slice_).set_properties(**{'background-color': '#ffffb3'}, subset=slice_)